
2024/12/27
On Thursday, October 10, 2024, a kickoff event for companies and research institutions selected under the "GENIAC" project, aimed at promoting generative AI development in Japan, was held in Osaki, Tokyo.
This article introduces comments from 20 developers selected for the computational resource support program and 3 companies selected for the newly launched demonstration project focusing on data and generative AI utilization.
Foundation Models Specialized for Diverse Industries and Fields Were Also Addressed
Presentations of Business Plans by Developers

At the beginning of the event, Takuya Watanabe from METI reflected on the progress of the GENIAC project, which supports generative AI development and business challenges based on its three pillars: (1) computational resources, (2) data, and (3) knowledge. He noted that the project has significantly strengthened Japan’s foundation for generative AI development.
Watanabe also emphasized the importance of accelerating social implementation, improving model performance, and advancing data utilization. He highlighted that the activities of the generative AI development community are essential to the success of the GENIAC project.
Below is a list of the developers selected for the second phase of the computational resource support program, along with their comments. This phase includes not only the development of general-purpose foundation models but also models and datasets tailored to specific domains such as automotive, pharmaceuticals, software development, business support, customer service, animation, food, environment, and tourism.
【List of Developers Selected for Cycle 2 of the Computational Resource Support Program】
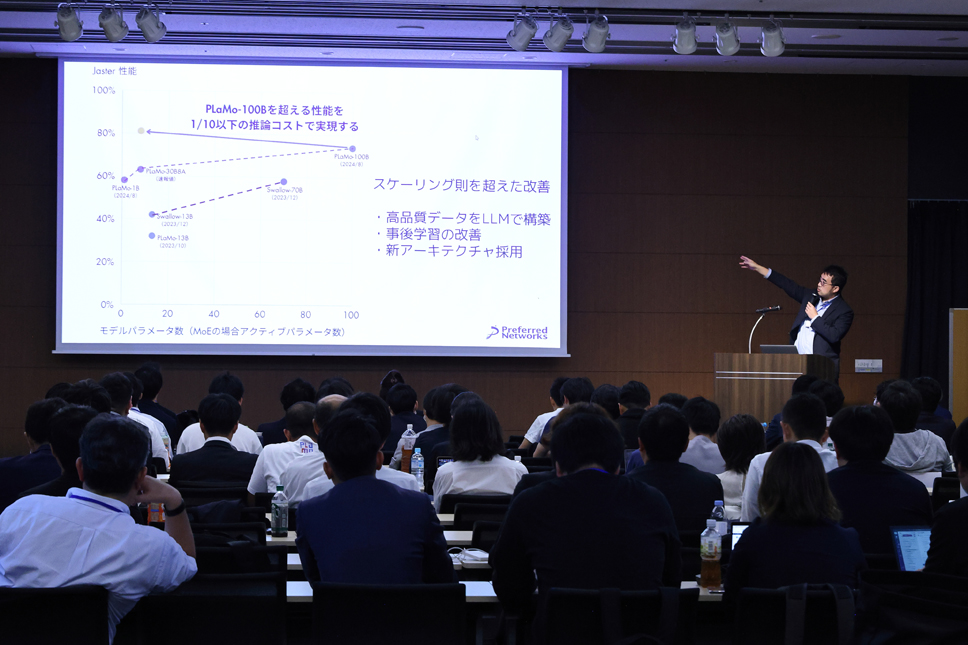

"In the first cycle, we developed a 100-billion-parameter LLM (large language model) from scratch, establishing a technology foundation for highly competitive large-scale models with high Japanese-language performance. In the second cycle, we aim to build one of the world's largest high-quality dataset by using our LLM and develop a MoE-based 30-billion-parameter LLM, reducing inference costs by more than 90%." (Okanohara)


"We successfully developed a high-quality multimodal AI model integrating vision and language and collected over 3,000 hours of 3D driving data during the first cycle. This time, we aim to build an AI model with 'embodiment,' integrating text, video, and sensor data to develop a fully autonomous driving system." (Yamaguchi)


"We aim to develop 'City-LLM,' a large-scale multimodal foundation model for urban environments. So far, we have released a dataset specifically focused on pedestrian accidents and served as organizers for the 'AI City Challenge' hosted by CVPR. Moving forward, we plan to conduct validation in real urban environments and contribute to global traffic safety." (Kobori)


"In the first cycle, we worked on developing foundation models for creating custom models, achieving a balance between low cost and high performance with precise RAG+Agent. In the second cycle, we aim to build two models, one with 10 billion parameters and the other with 50 billion, delivering world-class performance for specific tasks and implementing them on our platform." (Hattori)


"We are working on developing a lightweight large language model (LLM) specialized for the pharmaceutical domain, as well as creating datasets and evaluation benchmarks. The results of this project will be made public to the extent possible, and we plan to promote social implementation through our AI solutions, focusing on domestic pharmaceutical companies." (Sukeda)


"In this project, we aim to address challenges in AI-driven drug discovery by developing 'SG4D10B,' the world’s largest foundation model specializing in molecular information. This model will learn the 3D structural data of up to 10 billion compounds, with the goal of ranking in the top three on standard benchmarks in the AI drug discovery field. We will also verify drug efficacy and pharmacokinetics, as well as release large- and small-scale molecular foundation models." (Shimada)


"We are working to improve the success rates of drug discovery by developing a foundation model called ‘Cell Scribe,’ which learns gene expression data and consists of 300 million parameters. This model captures the cellular state space, aiming to drive progress in drug repositioning, safety assessment, and personalized medicine. I’m excited to engage in meaningful discussions with all of you." (Sese)


"We are advancing research and development on 'Personal AI' optimized for individuals. To enable real-time, accurate responses, high RAG performance is essential. In this project, we are working on building a 70-billion-parameter LLM with GPT-4-level response accuracy, as well as creating datasets for pretraining based on instruction data. Our ultimate goal is to realize Personal AI that complements human labor." (Hitomi)


"Through the development of character recognition utilizing AI-OCR and LLMs, we have been promoting the digitization of analog data held by companies. In this project, we aim to mass-produce SLMs with enhanced training data quality at a low cost. This involves building AI models that evaluate and automate reliability, expanding infrastructure, and improving inference efficiency through distributed processing." (Toguchi)


"We are developing a multimodal LLM (LMM) capable of accurately extracting information from documents including diagrams and images. Those documents are considered the 'essence of knowledge' within companies. This project aims to provide practical models that, while suitable for private LMMs within enterprises, retain long-context document comprehension capabilities and can be flexibly customized for company-specific needs. We are progressing with this effort in collaboration with our customers." (Hasegawa)


"We are working on building foundation models specialized in Japanese and software development, with parameter sizes of 8 billion and 70 billion. These models will support a wider range of tasks in the software development process, including detailed design and unit testing. We are also creating instruction-tuning and evaluation datasets. Furthermore, we aim to develop AI that supports programming education." (Morishita)


"We aim to build a high-precision AI agent specialized in Japanese-language customer support while minimizing hallucinations. Additionally, we will create learning datasets and evaluation benchmarks to support practical tasks and tool operations in customer support. Our goal is to accelerate AI implementation across the customer service industry." (Nakayama)


"We are developing a vision-based foundation model capable of selective editing for specific parts of videos and images, tailored to user intent. This model is primarily intended for use in industries such as manufacturing and advertising. To ensure safe and effective generative AI utilization, we are simultaneously working on developing AI for deepfake detection to prevent misuse." (Saito)


"To address labor shortages and long working hours in the anime industry, we are developing the world’s first Japanese-language anime video generation AI foundation model and video generation AI platform. We aim to establish an environment where lightweight models, operable on standard GPUs, can be widely used as open-source tools." (Tomihira)


"Our goal is to revitalize Japan’s anime industry by developing foundation models and production tools specifically designed for anime creation. To address the complex workflows of anime production, we aim to create an environment where AI can efficiently collaborate and streamline processes. Additionally, we plan to release an AI service for anime production companies that manages data and enables automated learning, making the model accessible for industry-wide use." (Tanaka)


"In the second term, we aim to develop a 100-billion-parameter multimodal LLM. This model is capable of understanding document comprehension of handling complex business documents used within companies with minimizing hallucinations. This model will support text, images, and Excel-like XML layouts, enhancing its ability to comprehend manufacturing and sales proposal documents." (Arima)


"We are developing a large-scale visual-language model with up to 70 billion parameters specialized for Japan’s food trends, aiming to significantly improve efficiency in industries related to food, retail, and distribution. In the future, we plan to implement a model capable of processing thousands of images or videos lasting several hours." (Shintate)


"We aim to develop a generative AI foundation model specialized to propose region-specific climate change adaptation and mitigation plans. By training on data related to meteorology, climatology, and disaster information, we plan to propose strategies for disaster risk prediction, prevention planning, and corporate climate strategies. In the long term, we aim to develop generative AI models specialized in earth sciences." (Matsuoka)



"We are developing a foundation model for the tourism industry that excels in East Asian languages, including Japanese, Chinese, and Korean. Portions of the developed model and datasets will be partly released as open-source to promote third-party application development. Additionally, we will provide tourism applications for municipalities and businesses, aiming to address tourism challenges and contribute to the sustainable development of the tourism industry." (Nakatsubo & Hirota)


"We continue to develop speech foundation models from the first cycle and plan to launch an API in six months that generates fluent Japanese speech in real time. In the second cycle, we are focusing on advancing from sequential interpretation to simultaneous interpretation and aim to establish a foundational speech technology platform in Japan and the Asia-Pacific region." (Kojima)
Investigation Project for Data Utilization and Generative AI Demonstrations for Solving Social Challenges Begins
In addition to supporting AI development through computational resources, a new initiative focusing on data and AI utilization has been launched.
SoftBank Corporation has been selected as the primary participant for a study on constructing new datasets to accelerate generative AI development. Safie Inc. has been chosen for a study on advanced examples of data and generative AI utilization, while OLM Digital Inc. was selected for a study on advanced use cases in industry-wide applications of generative AI.
【List of Organizations for Dataset Construction Research Projects】


"In this data demonstration project, we aim to accelerate generative AI development by constructing a Japanese-specific dataset for natural conversations. By setting scenarios in call centers and collecting diverse natural conversation data from approximately 30,000 participants, we strive to enhance the quality and productivity of Japanese generative AI. Although this is a challenging large-scale survey to be completed within a year, our goal is to create a highly useful dataset that can be utilized not only by AI developers but also by general businesses." (Fukuchi)


"We are developing an AI solution platform that leverages video data to solve various industry challenges. This project utilizes a vast amount of video data collected from over 260,000 cameras to establish many-to-many collaboration between data holders and AI developers, enabling efficient AI solution delivery. While ensuring strict privacy protection, we aim to contribute to the revitalization of Japan’s economy." (Morimoto)


"As the R&D department of an anime production company, we are conducting research on the utilization of generative AI. By employing AI as a tool and supporter for creators, we aim to improve the efficiency and quality of anime production workflows. This project will involve demonstration experiments to explore how AI can be integrated into processes such as keyframe and character drawing. By collaborating with multiple anime companies and research institutions in an 'ALL JAPAN' framework, we aim to contribute to the sustainable development of Japan’s anime industry." (Yotsukura)
After presentations by the developers, Masahiro Nakagawa from Boston Consulting Group (BCG), which supports the management of this project, provided an explanation of the objectives and past initiatives of the GENIAC community.

"The GENIAC community was established to share knowledge, build partnerships, and create rules. By facilitating knowledge sharing among developers and holding matching events with user companies, the community promotes efforts toward social implementation." (Nakagawa)
To conclude the kickoff event, Kazuyuki Takada from NEDO (New Energy and Industrial Technology Development Organization) spoke about leveraging NEDO’s various support programs to further accelerate the initiatives of the selected developers.

"How generative AI is integrated into Japan’s industries and society will be a key focus moving forward, particularly in areas such as mobility, healthcare, and digital content. We expect the developers to enhance their global competitiveness while leveraging NEDO’s various support programs." (Takada)
After Takada’s concluding remarks, a group photo session was followed by a networking event where participants, including developers and stakeholders, engaged in lively conversations in a friendly atmosphere.


GENIAC’s kickoff event for selected developers featured presentations of business plans by developers in the first part and a networking session in the second part.
Stay tuned for GENIAC’s future activities!
Last updated:2024-02-01