
2024/9/2
2024年5月21日(火)、2024年2月公募にて採択された事業者のKick Offと、2023年11月公募にて採択され2024年2月から実施中の事業者による中間報告会をオンラインで開催しました。
前半はGENIACの目的や概要の説明、各採択事業者からの事業紹介と取り組む開発についての発表が、後半は2023年11月公募の採択事業者、4社による中間報告と、それに対する質疑応答が行われました。
本記事では、当日の内容の一部を紹介します。
国産LLMが日本、そして世界を変えるために
はじめに、2024年2月公募の採択事業者へ向け、経済産業省ソフトウェア・情報サービス戦略室長 渡辺 琢也氏が本事業の目的・概要とコミュニティの役割などについて説明しました。
「世界には、自然災害や長時間労働など様々な課題があります。このような多くの課題を解決する可能性がある生成AIが、普及しようとしています。しかし、今はまだ黎明期。安全に幅広い分野で利用するためには、まだまだ取り組むべきことがあります。日本が安全に、より広い分野でAIを利用しイノベーションを創出し続ける。そして豊かで、誇るべき国となるためには、生成AIの開発力が重要であり、皆様のような高度なソフトウェア開発人材が活躍することが不可欠です。日本の生成AIの持続的な開発力の確保に向けて、生成AIの開発力の底上げを図るとともに、それぞれのビジネス主体が創意工夫し、挑戦できる環境をつくっていくのが本プログラムの目的としています。本プログラムは生き物です。皆様とともに大きく育っていくことを願っています」(渡辺氏)
続いて、日本マイクロソフト業務執行役員の大谷氏から、2024年2月公募の採択事業者への挨拶がありました。
「今回採択された3社の皆様、誠におめでとうございます。これからLLM(大規模言語モデル)の開発が始まっていきますが、マイクロソフトはクラウドベンダーとして、今回GPUとそこに関わる様々な周辺ソリューションを提供することによって、皆様が1日でも1秒でも早く、より良いLLMを開発いただけるようなご支援をしていきます。生成AIが脚光を浴びてから1年半近くが経ち、企業などでも使われるようになってきた中で、少しずつ見えてきているのはマルチなLLM、SLM(Small Language Model)の必要性が高まってきていることです。また、テキストだけでなく、音声や画像・映像といったマルチモーダルでの利用が社会から必要とされています。最終的には一つのLLMではなく、様々な用途に合わせたLLMやSLMが必要になっていく中で、まさに国産LLMが世界に羽ばたいていくご支援を、マイクロソフトができたらと考えています。我々も独自のSLM「Phi-3」を、最近リリース致しました。そういった開発ノウハウもぜひこのプログラムを通して提供し、一緒にLLM開発を進め、日本を元気にして社会実装に結びつけていきたいと考えています」(大谷氏)
採択事業者、3社が新たにGENIACに参画!
次に、2024年2月公募の採択事業者が事業内容の説明を行い、今回の採択を受けて取り組む開発について説明をしました。
追加3採択事業者
- 株式会社ELYZA
- 株式会社Kotoba Technologies Japan
- 富士通株式会社
それぞれの発表内容の一部を紹介します。
株式会社ELYZA
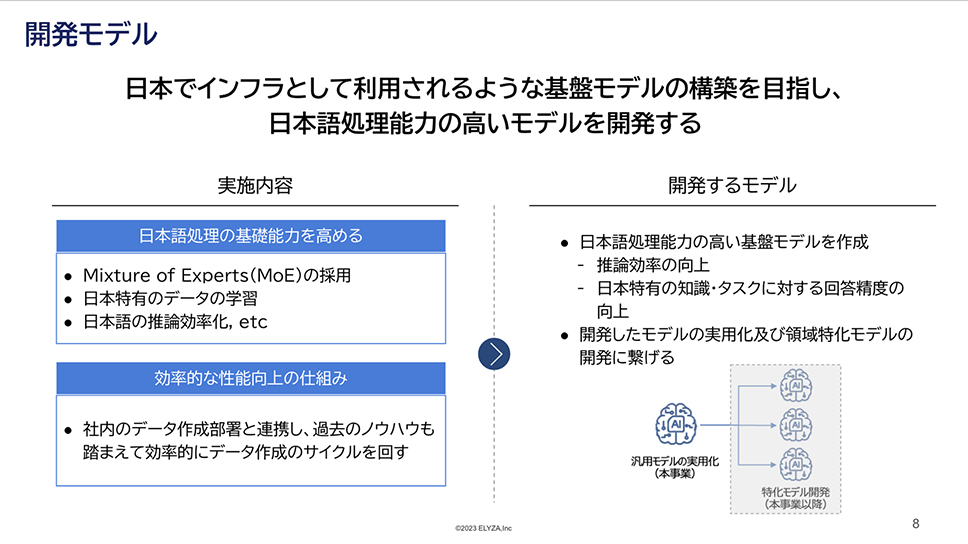
株式会社ELYZAは、LLMを用いて、ホワイトカラー業務のDXに取り組んでいる企業です。2019年から、LLMについて研究開発・社会実装の両軸で活動しています。同社はこれまでも、アプリケーションや研究成果を国内で発表してきました。2024年3月には、700億パラメータのモデルを構築し、デモサイトを公開しています。社会実装にもこだわっており、実際にLLMの導入により業務効率を30〜50%ほど効率化する事例が多く産まれているといいます。
「今回、日本でインフラとして利用されるような基盤モデルの構築を目指し、日本語処理能力が高いモデルを開発していきます。日本語処理の基礎能力を高めるために、MoE(Mixture of Experts)の採用、日本語特有データの学習、日本語の推論の効率化を行っていきます。また、弊社にはデータ作成部署があるため、そこと連携をしながら、過去のノウハウを踏まえ効率的にデータ作成のサイクルを回していきます。また、このプロジェクトでの成果を踏まえて、日本語汎用モデルの実用化、及び領域特化モデルの開発、展開にもしっかりと繋げていきたいと考えています」(株式会社ELYZA 取締役CTO 垣内 弘太氏)
株式会社Kotoba Technologies Japan
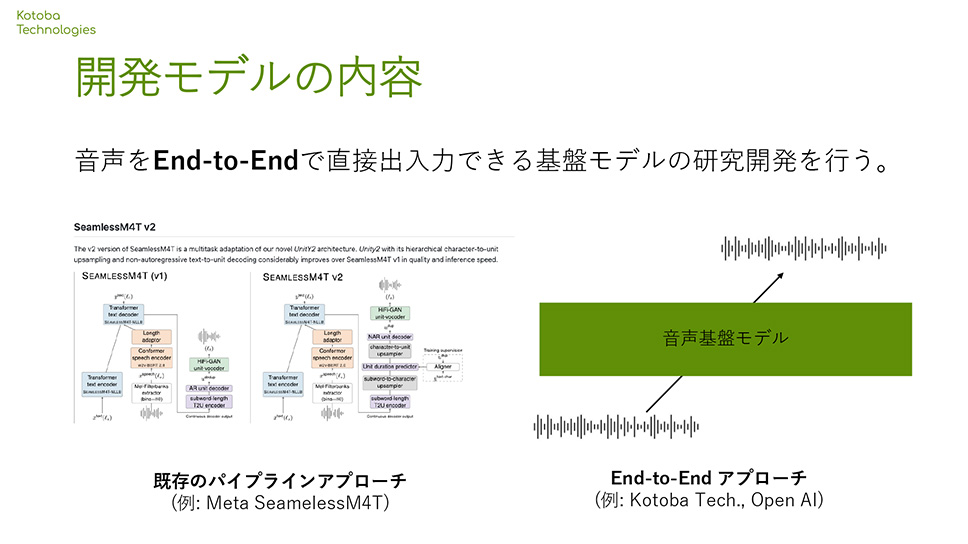
アメリカのアカデミアで生成AIの研究を行ってきたメンバーによって2023年に創設された、株式会社Kotoba Technologies Japan。同社は、スーパーコンピュータ「富岳」を使ったLLMの開発に携わり、現在は日本語の音声生成と認識における最先端モデルの開発も行っています。
「GENIACのプロジェクトでは、音声の波形を直接入力し、end-to-endで直接出力できる日本語と英語に特化した音声基盤モデルの研究開発に取り組みます。end-to-endの音声基盤モデルは、世界的に見てもなかなか開発が進んでいません。70億パラメータまでの基盤モデルを、大規模な日本語と英語の音声データによって学習し、そのうち一部のモデルを公開することで、コミュニティに大きく貢献していこうと考えています。開発したモデルをデモとして公開することによって、アプリケーション開発へのイメージを皆様に強く持っていただいき、フィードバックいただきながら、安全性への取り組みも行っていきます。弊社と東北大学との共同プロジェクトとして、弊社の笠井淳吾と、東北大学の坂口慶祐教授がチームリーダーとなって、音声モデルの学習データの収集と評価で、役割分担をして取り組んでいきます」(共同創設者 & CEO 小島 熙之氏)
富士通株式会社
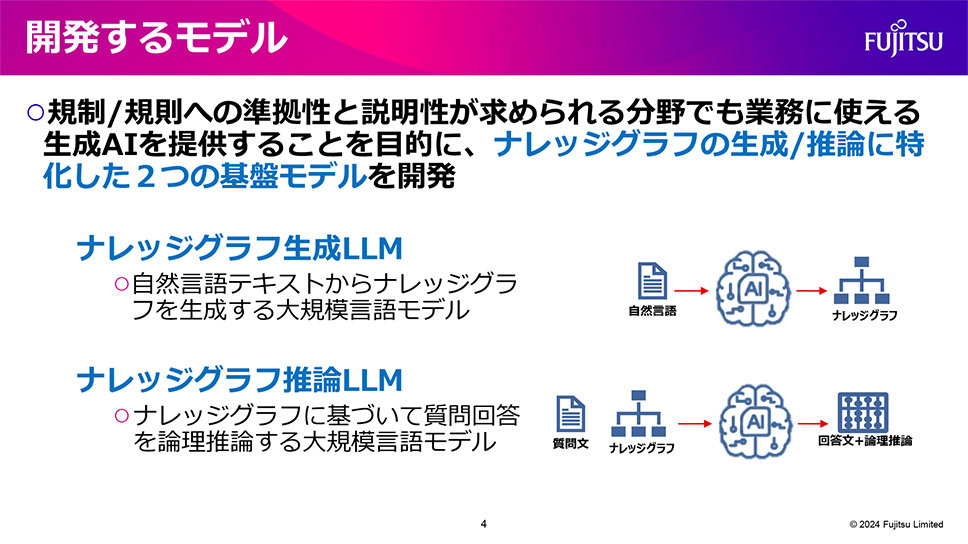
スーパーコンピュータ「富岳」をはじめとしたハードウェアの開発や、AIの技術を活用したDX実現のサポートを行う、富士通株式会社。近年では社会実装を前提とした生成AIの研究開発に力を入れており、実際に業務に使用できる信頼性の高い特化型モデルの開発に取り組んでいます。
「今回、ハルシネーションなどの課題に対して、信頼性を高めるモデルの開発に取り組みます。具体的には、法律などをはじめとした規制規則、あるいは企業のガイドラインに準拠した出力ができ、説明性が求められる分野でも業務に使えるモデルです。その中でも、ナレッジグラフの生成と推論に特化した基盤モデルの開発が重要だと考えています。自然言語とナレッジグラフを組み合わせた事前学習を行い、その上でファインチューニングをしていきます。論理推論が必要なタスクにおいても正確に回答できることを目指していきます」(富士通株式会社 人工知能研究所 シニアプロジェクトディレクター 白幡 晃一氏)
トラブルを乗り越えながらも成果を達成!
続いて、基盤モデルの開発を進める次の4社の採択事業者が中間報告を行いました。
中間報告を行った採択事業者
- 株式会社ABEJA
- ストックマーク株式会社
- Turing株式会社
- 株式会社Preferred Elements
それぞれの発表内容の概要と、発表者のコメントを紹介します。
株式会社ABEJA

株式会社ABEJAでは、データ・前処理、モデル開発・学習、インフラを担当するチーム体制で、Mixtral 8x7 Billionの日本語語彙拡張版継続事前学習を実施。開発ではMegatron-LMとHugging Faceを使用したため、双方向の変換スクリプトを作成しました。
報告概要
- 語彙拡張前のtokenizerでは約400B token(英語、ソースコード約126B token、独自収集の日本語データ約30B token)のデータを使用。
- Mixtral 8x7 Billionを利用して継続事前学習を、Ubuntu on GCEで開発・検証(分散学習の動作確認)、GKE on COS で本学習を実施。
- 学習後徐々にLossがNaN(非数)になるトラブルは、fp16からbf16にすることで解決。
発表者のコメント(一部抜粋)
「環境構築、モデル開発、nan 現象、通信エラー、ノード不良など、よく当たる課題は大方経験したため、お困りごとがあれば気軽に弊社にお問い合わせいただければと思います」(株式会社ABEJA 中西 健太郎氏)
ストックマーク株式会社

ストックマーク株式会社では、厳密さが要求されるビジネス用途におけるハルシネーションを大幅に抑止した基盤モデルをテーマに開発を実施。同社が独自に収集したビジネスドメインの知識を使って事前学習を行うことで、正確性の高いモデルの開発に取り組んでいます。
報告概要
- 日本語は公開されているデータセットに加え、同社が独自に収集しているビジネスドメインのデータセットを合わせた3050億トークンのテキストデータを使用。英語はRed Pajamaのデータセット(Books除く)からサンプル。
- 48ノードのA3インスタンスで、1000億パラメータ規模のLlama 2のモデルを学習。
- 前半での学習の進み方(lossの減少)が想定よりも遅かったが、最後に日本語の割合を多くして学習することで対応。
- プロセスエラーに対しては、ある程度プロセスが止まってしまうことを前提に、自動的な復旧の検知、メンテナンス時の対応、ノード不良の際にどう対応していくかを事前に決めておくことが重要。
発表者のコメント(一部抜粋)
「今回開発しているモデル自体も公開しており、デモも用意しています。興味のある方はお試しいただければと思います。皆様へのメッセージとしては、精神的にも肉体的にも大変なワークロードだとは思いますが、できるところは事前に準備をして、頑張っていただければと思います」(ストックマーク株式会社 近江 崇宏氏)
Turing株式会社

Turing株式会社では、マルチモーダルAIを用いた自動運転の実現に取り組んでいます。マルチモーダル学習、運転ドメインへの適合、分散環境による大規模化を目指します。
報告概要
- GCP(Google Cloud Platform)の「HPC Toolkit」を利用。blueprintを利⽤することでGCP環境に最適化した⼤規模計算環境を構成できる。
- ベースモデルにSwallow-MS-7b (Mistral-MS-7b)と、Llama3-8b(学習中)を使用。
- データは、Google ResearchのFlanデータセットに回答を付与したものがベース(英語)。5万件を機械翻訳で⽇本語の指⽰チューニングデータに(100M token程度)。
- ⽇本語LLMの初期モデル(heron-brain-7b)を構築。7Bクラスでは公開されているモデルと比べ、最高の日本語性能となった。
発表者のコメント(一部抜粋)
「6月中旬から35ノードで、大規模なVLM(Vision-Language Model)学習を行っていこうと考えています。その中でやはり自動運転の適用が大きいポイントになるため、より大規模なモデルの学習、運転ドメインへの適合を目指しているところです。継続的に実験が回せる堅牢な学習環境が大事だと改めて感じています。また、『モデルやデータを簡単にスケールするものではない』というところも改めて感じていますので、スモールスタートで、小さく始めて試行錯誤するのが意外と近道かもしれません」(Turing株式会社 ⼭⼝ 祐氏)
株式会社Preferred Elements

株式会社Preferred Elementsでは、「100Bモデルの事前学習・追加学習」「100Bモデルの指示学習」「画像モーダル向けの事前学習・追加学習」「音声モーダル向け追加学習」「1Tモデルの事前学習の検証」の5つを目標に開発に取り組んでいます。その中でも、「100Bモデルの事前学習・追加学習」については事前学習がほぼ完了し、5月13日時点で日本語性能を評価する標準的なベンチマーク Jaster 4shotで0.71を記録しています。
報告概要
- GCPメンテナンスや不調による中断・復帰が断続的に発生したが、対策済み。
- 100Bモデルは指示学習を7月中旬まで実施し、指示学習終了時は日本語ベンチマークで最高性能を狙う。
- 1Tモデルは、7月中旬から8月15日までの約1か月で、MoE手法の確立、実装、最適化及びモデル性能の確認を実施する。
発表者のコメント(一部抜粋)
「今回のモデルの公開については、いろいろなかたちで検討しています。既存モデルをベースに用いず、事前学習からすべて新規に開発している中で、想定外リスクの可能性にも備え、安全面について様々なところと協力し検証しながら進めたいと思っています。事業化も並行して進めているところです。今回つくったモデルで終わりではないので、さらにその次のステップ、事業化へ向けて取り組みを続けていきます」(株式会社Preferred Elements 岡野原 大輔氏)
それぞれの採択事業者の報告の合間には活発な質疑応答が行われ、質問者の具体的な課題を解決するための知見が共有されました。
今回の中間報告会では、各事業者が互いの知識をさらに深め、今後の開発に生かせる有益な情報を得られる貴重な時間となりました。引き続き、各事業者が創意工夫を凝らし、さらなるイノベーションを追求することにご期待ください。
GENIACトップへ最終更新日:2024年9月2日