
2025/1/22
GENIACは今後、さらに日本の生成AI開発を支援
2025年1月21日(火)、生成AI基盤モデルの開発を手掛ける、計算資源の提供支援事業 第2期 採択事業者20社による中間報告会を開催しました。本会は、これまでの開発進捗および中間成果を報告し、事業者間で学びの共有を行うことを目的として実施されました。本記事では、当日の内容の一部を紹介します。

はじめに、経済産業省 商務情報政策局 情報処理基盤産業室 室長 渡辺 琢也より、GENIACの今後の展開と、本日の報告会の位置づけを説明しました。
「GENIACは、日本の生成AIの持続的な開発力を確保するプログラムです。GENIACでは今後、計算資源の提供支援事業の第2期として、一定の分野のデータを質的量的にかつ継続的に拡大させるための支援をしていきます。また、3月中旬から公募が始まる計算資源の提供支援事業 第3期では、社会実装をより見据えた競争力が見込まれる開発を重点的に支援したいと考えています。さらに、懸賞金型AIサービスの開発促進として、アプリケーションにおける個別のユースケースをテーマに設定した事業を、本年夏に公募開始する予定です。加えて、東南アジアやインドなど、グローバルサウスへの展開もサポートを開始していく見込みです。本日は、計算資源の提供支援事業 第2期の中間報告です。ぜひこれまでの開発を自ら振り返っていただくと共に、他の開発事業者の開発や狙いを学びとして、今後に生かしていただけたらと思います」(渡辺)

続いて、GENIACの採択事業者が進める、国産の大規模言語モデル(LLM)の開発を資源・技術など多角的に支援している、アマゾン ウェブ サービス ジャパン合同会社 常務執行役員 サービス&テクノロジー統括本部 統括本部長 安田 俊彦氏より挨拶があり、「弊社が関わっている本プログラムの成果が、どのようなかたちで出ているのか、本日お伺いするのが大変楽しみです」と、中間報告会への期待をのぞかせました。
中間報告会
今回の中間報告会は、計20社からの報告がありました。
- 株式会社データグリッド
- フューチャー株式会社
- NABLAS株式会社
- Turing株式会社
- ウーブン・バイ・トヨタ株式会社
- 株式会社リコー
- AI inside株式会社
- ストックマーク株式会社
- 株式会社AIdeaLab
- AiHUB株式会社
- 株式会社ユビタス/株式会社Deepreneur
- 株式会社Kotoba Technologies Japan
- カラクリ株式会社
- 株式会社ABEJA
- 株式会社Preferred Elements/株式会社Preferred Networks
- 国立研究開発法人海洋研究開発機構
- 株式会社ヒューマノーム研究所
- 株式会社EQUES
- SyntheticGestalt株式会社
株式会社データグリッド

株式会社データグリッドは、2017年に創業した、京都大学発の生成AIスタートアップです。以来、画像生成や動画生成の領域にフォーカスして、生成AIの事業を展開してきました。GENIACでは、動画に関する汎用的な基盤モデル、画像に関する汎用基盤モデル、そしてそれらを有効利用したディープフェイク検知モデルの開発の、3本柱で開発を進めています。2024年10月からスタートした開発は、画像生成基盤モデルは、低解像度(256x256)の学習が完了し、中・高解像度での学習中。ディープフェイク検知AIに関しては、基盤モデルを活用した特徴量の探索の検証を開始しました。中間までの計画と成果はほぼ予定通りに推移しており、「画像生成AI」分野においては、当初1,000万件での構築を予定していた画像データセットが2,000万件を超えるなど、計画以上の成果を上げています。一方で、開発中に分散学習の学習速度が遅いという課題に直面しましたが、網羅的な検証、インフラの最適化、DALIの活用でその課題を乗り越えることに成功しました。また、動画データの収集に想定以上の時間がかかっていますが、今後、半自動化によって改善予定です。
フューチャー株式会社

フューチャー株式会社では、日本語とソフトウェア開発に特化した基盤モデル(8Bおよび70Bパラメータ)の構築を進めています。現在は、日本語とソフトウェア開発に特化した8Bパラメータの基盤モデルを構築していますが、開発の開始前に使用を決めていた日本語・コードデータが非常にノイジーで、そのまま学習させただけではベンチマークスコアが下がり続けてしまうという課題に直面しました。しかし、データ生成・フィルタリングの試行錯誤を繰り返し、一部のベンチマークではベースモデルである「Llama 3.1」を超える精度を達成しました。その中で、LLMは学習中に評価値が大幅にブレること、データクレンジングは目視と根気が重要であり、ノイジーなデータを探し、それを除去するルールを書くというノウハウを獲得しました。今後は、データのフィルタリングおよび学習を継続しながら、一定程度の8Bモデルの精度が出ることを確認し、70Bの学習に移る予定です。また、データクリーニング法については蓄積したノウハウを共有すべく、ドキュメントとしてまとめ、公開することを検討しています。
NABLAS株式会社
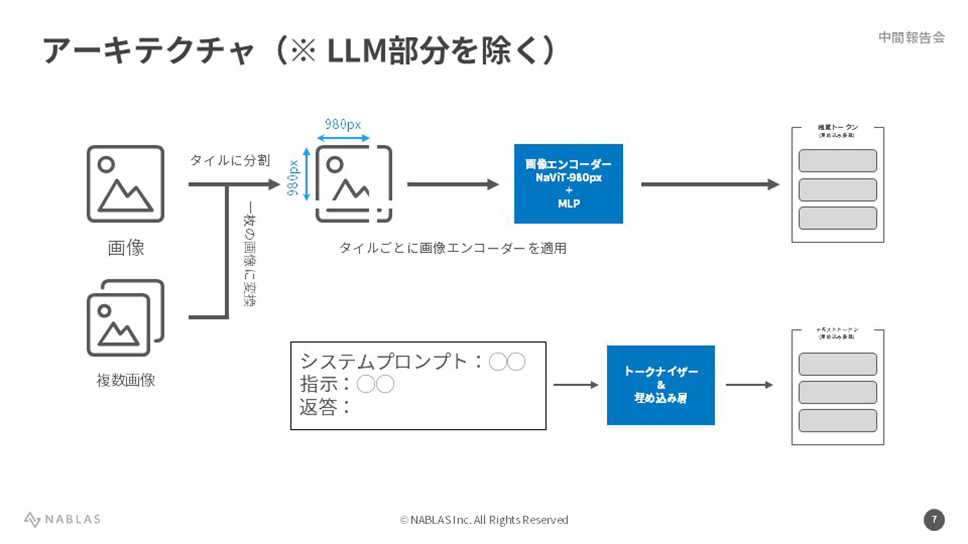
NABLAS株式会社では、(1) 汎用的な大規模視覚言語モデルの開発と、(2)「日本っぽい」/「流行りの」食品に特化した大規模視覚言語モデルおよび、それらを利用したサービスの実証実験を行うことを主な目的としています。目標は2つあり、1つは、同ドメインのベンチマークでその他モデルを上回ること。もう1つは、得られた知見を用いてAIの観点から小売・流通の業務を効率化することです。これまでの成果として、5M(サンプル数)規模のデータセット上で8Bモデルの構築を完了後、独自作成した300枚程度のデータセット上で8BモデルのSFTを行いました。さらに直近では、単一画像・複数画像・動画からなる10〜15M規模のデータセットを構築して15Bモデルの学習を開始しました。今後は、学習データセットの改善、MoEモデルの学習、独自構築した6,800枚規模のデータセット上でSFTを行うことを計画しています。
Turing株式会社

Turing株式会社は、人が介在しない、完全自動運転の技術を開発しているスタートアップです。GENIACの第1公募にも参画しており、今回の第2公募では、実際に完全自動運転で車を動かすことをテーマに据えています。今回、3つの項目に取り組んでいます。1つ目は、高度なVLMのモデルの構築。2つ目は、自社で車を走らせ、⾃律移動視点の大規模三次元データの収集と整備。3つ目は、この2つを組み合わせて、テキストのみでは獲得が難しい⾝体性を学習させること。これまでに、⼤規模データセット「OBELICS-JA」の構築を進め、⽇本語と英語の⾔語と画像を収集するとともに、膨大なデータ処理の高速化、並列処理をする仕組みを構築しました。また、GENIACの第1公募で構築した「Cauldron JA」のVLMによる追加の合成データを作成するコードを実装。加えて、完全自動運転に必要な視覚-⾔語マルチモーダルモデルの開発を進めており、⼤規模データに対する効率的な学習パラメータの検証を進め、「Heron-Bench」によるVLM性能の学習では、評価サイクル⽬標の4.0以上を達成しました。現在は、⾃動運転シミュレーション環境の整備を進めています。
ウーブン・バイ・トヨタ株式会社

ウーブン・バイ・トヨタ株式会社は、都市時空間理解向けのマルチモーダル基盤モデルの構築に取り組んでおります。都市の状況を『時間』や『場所』といった側面で理解し、『人の行動/ mobility of people』を促進する世界を創出していきます。そのために、6億の動画像+言語のデータセットを構築、7Bレベルモデルの開発を進めてきました。成果は3つ。1つ目は、6億の動画像+言語データセットの構築です。品質にこだわり、独自の50種類以上のフィルタによるデータの高品質化を進め、計画の83%を完了しました。また、動画像向けインスタンスレベルのキャプションを大規模に構築しました。2つ目は、分散学習環境の構築です。分散学習基盤は「DeepSpeed @ GKE(Google Kubernetes Engine)」を採用し、DeepSpeed ZeRO2、DS ZeRO3の順で実装とテストを実施済です。3つ目は、動画像理解向け基盤モデルの開発です。約20Mの動画像+言語データと、約2Mの指示学習用データを用いて学習を実施。動画像と全体説明文を用いて、事前学習から指示学習までマルチステージ学習を行い、継続的な学習ができることを確認しました。事前学習から指示学習まで、それぞれのステージへ単体評価を実施し、「事前学習した動画像エンコーダで行動理解のデータセット(Kinetics400)」での評価において、目標とした80%を上回る85.41%の精度を出せました。今後、構造化データの追加学習などによって、大規模のデータ、モデルサイズと言語モデルの構造の拡張・アップデートを目指します。
株式会社リコー

株式会社リコーは、企業のドキュメント理解に特化したマルチモーダルLLMの開発を進めています。これまでに、小型のマルチモーダルを使用して、性能の見積もり、モデルの改善を進めてきました。成果として、5つの開発を行い、小型モデルにて学習/評価を実施。また図表の読解力を測る独自ベンチマークにて性能向上を確認しました。実施した開発は、Qwen/LLaVAに搭載されている各種高解像度化手法の移植と評価、「QwenViT」と「Llama」を組み合わせたモデルの作成、複数回の学習による知見の獲得、「LLaVA-OV」から商用利用不可の学習データを除外した上で商用利用可能なデータを増強、「LLaVA-OV」の性能向上を確認、図表の読解能力を評価する独自ベンチマークの構築完了(今後の改良も予定)の5点です。これにより、大枠の方式はおよそ決まり、今後、小型モデルで得た知見をかし、大型のマルチモーダルLLMの学習を実施予定です。また、今日までに得られたノウハウとしては、画像がVEを通り、どのようにLLMに入力され、どのように理解されているのかという一連の機能の流れ、各種高解像度化のための手法、ドキュメント画像に適応したときの改善点などが挙げられます。
AI inside株式会社

AI inside株式会社は、AI-OCRを提供している会社です。GENIACでは、汎用的に非構造化データの構造化ができる生成AIモデルの構築を目指しています。現在、SLM自動生産を目指し、非定型帳票のAI-OCRの認識精度に対して、誤差部分の30%の精度向上を実現しました。同時に、分散処理基盤の構築を進め、同等の計算リソースにおける処理能力を従来の10倍に向上させました。全体としては、一般項目の精度は89.86%から92.22%に向上。明細項目の精度は76.00%から83.94%に向上しました。データセットの構築に関しては、これまで非定型20万枚で学習。基盤モデルの改善においては、社内帳票データでファインチューニングし、社内評価データセットで評価を実施。現行サービス中のLLM(PolySphere-2)に対して精度+1.83%のモデル学習に成功しました。項目抽出機能の開発に関しては、現在、LLMへの入力データとなる明細表を以前より正しく整形することで、精度の改善が見込めることを確認。精度91%ほどまで改善することができました。2段階生成AIアーキテクチャを採用しているため、SLM 蒸留技術の開発を進めており、SLMのLatencyを30%短縮化、処理能力を最大13倍に向上させました。また、チェックボックスによる項目の選択状態を認識する精度が低いという問題を改善。検出精度精度が55.6%から93.1%まで向上しました。
ストックマーク株式会社

ストックマーク株式会社は、ビジネスで使えるAIをつくることを目指して研究開発を行っている企業です。読解が難しい、創造性あふれるビジネス資料の読解を可能にするために、100Bパラメータ規模のマルチモーダルドキュメント読解基盤モデルの開発を目指しています。100Bパラメータ規模のLLMの事前学習の検証においては、100BパラメータのLLMの最終的な性能を向上させるための事前学習の知見が十分にないという課題に直面。しかし、本番相当のデータで15Bのモデルの事前学習を行い、学習が問題なく進むことを確認し、問題を解決することができました。当該LLMの事前学習とチューニングにおいては、100Bトークンごとに「JASTER 4-shot」による評価を行い、モデルのサイズに応じて性能が向上していることを確認しました。マルチモーダル学習(データセット構築)に関しては、ビジネスドメインのスライドを収集し、説明文やQAのアノテーションを行っているところで、今後5万件のスライドも予定しています。また、ドキュメントをカテゴリーごとに分類し、200件程度の評価ベンチマークの雛形を作成しました。今後は学習データの質の向上などによって、性能アップを目指します。
株式会社AIdeaLab

株式会社AIdeaLabは、AIとIdeaをかけ合わせ、革新的なプロダクトを連続的に生み出すスタートアップスタジオです。開発当初から、動画のアノテーションを継続的に行っており、それと並行して順次、軽量モデル、汎用モデル、アニメモデルの開発を予定しています。現在、成果として軽量モデルが完成したので、デモとして公開。軽量モデルに関しては、当初1Bを予定していましたが、性能が足りず、2Bに増やして対応中です。これまでに得られたノウハウは、Rectified Flow Transformerが画像生成だけでなく動画生成でも有効であること、動画からのフルスクラッチでも学習が可能であることです。同時に、動画用のRectified Flow Transformerの学習用ソースコードがないという課題に直面しましたが、最先端のソースコードを組み合わせることで解決することができました。
また、学習データである動画が足りないという問題もありましたが、「FineVideo」など他のデータセットから抽出することで対応しました。
AiHUB株式会社
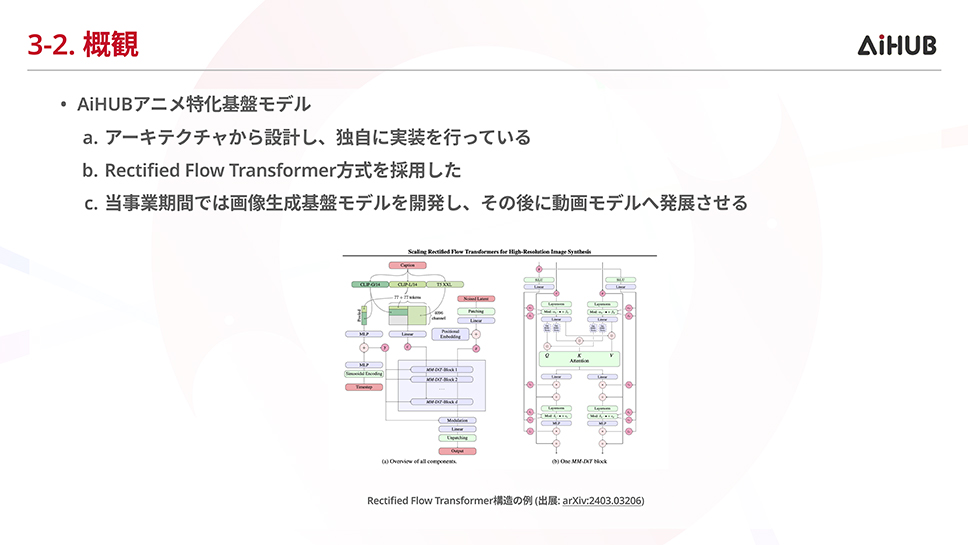
AiHUB株式会社は、画像生成AIのコミュニティ、オープンソース開発者のコミュニティが合流して2023年に誕生した会社です。GENIACでは、日本アニメ産業活性化のためのアニメ特化型基盤モデルの開発に取り組んでいます。この事業の構成は2段階になっています。まず、基礎となる共通基盤モデルを開発。次に、アニメ制作会社やアニメスタジオなどが所有するデータを追加学習します。そして事業者が自身のデータを用いた安心して使える「事業者ごとの専用モデル」と、アニメ事業者様向け「アニメ特化生成AI サービス」を事業者へ提供することで社会実装を推進します。なお、この期間では、画像生成基盤モデルを開発し、その後に動画モデルへ発展させる予定です。学習段階は試験・本番の2段階に分かれており、現在は「事前学習の大規模試験段階」にあります。開発中には、オートエンコーダーの独自の設計と学習を行い、PSNR評価にてnvidia/Cosmos-0.1-Tokenizer-CI16x16を4%程度上回る性能(26.38)を達成しました。他にはテキストエンコーダーの比較を行うなど画像モデルとしての出力向上に向けた開発知見の蓄積を行う事ができました。また、現時点ではアニメドメインのデータの確保が十分な量に至っておりませんが、引き続き、データの確保や本番段階の学習を進めて、本事業の成功を目指してまいります。
株式会社ユビタス/株式会社Deepreneur

株式会社ユビタスと株式会社Deepreneurは、観光に特化したLLM/基盤モデルの開発に取り組んでいます。特に、日本語、中国語、韓国語に強い、多言語LLM基盤モデルの開発・公開を目指しています。今回、まずは日中韓の3言語を含む多言語データセットを構築し、観光領域での利活用に向けたファインチューニングを実施。様々なデータ生成とクリーニング方法を通じて、トレーニングとデータ品質を向上させてきました。成果として、webクローリング、データ生成、ノイズ除去、CoTリワイヤリングなどを用いて40B以上の繁体字中国語を取得。日本語の大規模コーパスの作成と小規模モデルでの予備実験を行い、「TMMLU+」で76.06%、「Llama 3.3 70b」で目標の68%を達成することができました。本モデルでは、中国語と日本語のデータセットを別々に作成しており、日本語に関しては、継続的な事前学習に100B規模の日本語データセットを使用しています。このデータセットは、高品質なテキスト(公式文書、ニュース記事、学術論文)、第三者からの評価が高いテキスト、webクローリングを基に簡易的なフィルタリングを行ったテキストで構成されており、性能向上に貢献しています。今後、日本語、中国語と韓国語のデータセットを融合し、複合学習を行っていく予定です。
株式会社Kotoba Technologies Japan

株式会社Kotoba Technologies Japanは、リアルタイム音声基盤モデルを構築するプロジェクトを推進しています。このプロジェクトでは、2段階のステップを踏みます。まず、日本語を中心とした、高品質音声データセットを構築します。TTSモデルを学習・活用して20万時間の音声を生成し、その他のリソースから日本語データ20万時間を収集してクリーニングします。同時に英語を中心とした20万時間分の高音質データを収集しクリーニングをします。次に、このデータに音声基盤モデルを学習させて、高速推論やLong-from/Two-Stream推論などのChatbot的な汎用性に加え、同時通訳などのアプリケーションにつなげます。TTS/音声基盤モデルは、トークナイザーを活用して音声を離散化して学習・処理する仕組みですが、現状の成果として、離散化の圧縮率を5〜6倍向上させることに成功し、学習の高速化を実現しました。すでに多言語音声生成に関しては高い性能を誇り、日本語の音声をそのまま変換可能です。同様に、音声同時通訳では、日本語で話していた音声をほぼリアルタイムで、多言語に変換することが可能となっています。今後もユーザーフレンドリーなAI開発を進めていく予定です。
カラクリ株式会社

カラクリ株式会社は、チャットボットツールなどを手掛ける、AIスタートアップです。GENIACでは、カスタマーサポートに特化した高品質AIエージェントモデルの開発に取り組んでいます。当初の計画では、カスタマーサポートのAIエージェントモデルをつくるための学習データ・ベンチマークの作成、モデルの学習・評価、モデル・ノウハウ・ベンチマークの公開を予定していました。中間の成果として、データセットの構築においては、画像を含む日本語データセットの構築、日本語コンピュータ操作データセットの構築。また、コンピュータ操作を記録するツールを作成。どちらも日本語のカスタマーサポートのエージェントモデルの開発に必要なデータが世の中にはなく、自作していくことで、課題を乗り越えました。業務で培ってきたノウハウを生かし、パターンを洗い出して合成データとして作成しました。コンピュータ操作に関しては、記録ツールをつくり、効率的にデータを収集できるように。学習においては、Trainiumでの学習の予備実験(InternVL 2.5, Qwen2VL, QwQ)を実施。今後、公開を目指していきます。他に、AWSのサポートを得て、AWS Marketplaceへの載せ方を知ることができたことも大きな収穫となりました。
株式会社ABEJA

株式会社ABEJAは、ビジネスに特化した、高性能でありながらパラメータサイズの規模を抑えたLLMの開発に取り組んでいます。50B以下と10B以下、2サイズのモデルをつくる予定です。今回、ベースモデルとして「Qwen2.5」を利用し、開発フレームワークには「NeMo」を利用しています。学習データは約100Bの日英データ(日本語7割、英語3割)。現在、50B以下、10B以下ともに第1弾の学習は完了しており、ベンチマーク評価も好調で、順調に開発は進んでいます。直面した課題としては、「Qwen2.5」の性能は高いものの、ときどき中国語を出力してしまうケースがありました。これについては、継続事前学習での解消に期待しましたが、まだ解決には至っていません。原因の仮説としては「元モデルのChatVector適用により発生」「Qwen自身の合成データで中国語混ざりも学習してしまっている」の2つが考えられます。Post-Trainingで1つ目に対応をしながら、中国語の出力をしてしまった(出力を誤りやすい)データを、日本語としてActive Learning的に学習することで2つ目の仮説にも対応していく予定です。一方で、データ量よりも品質を重視し、その中で、合成データは、他のデータとの組み合わせの工夫がないと多様性が生まれないといった知見を得られました。
株式会社Preferred Elements/株式会社Preferred Networks

株式会社Preferred Elements/株式会社Preferred Networksは、世界最大規模の高品質なデータセットの構築および大規模言語モデルの開発に取り組んでいます。GENIAC第1期で開発したLLMを活用して高品質なデータを100Bトークン作成する目標は既に達成。現在は200Bトークンを作っています。特に日本語による知識、数学、プログラムコードなどを重点的に作成。全体の進捗も計画通りに進んでおり、これまでに1Bモデルの構築が完了しています。現在は8Bモデルを学習中です。その後、30Bモデルの学習を行う予定となっていますが、より挑戦的な目標として30B(アクティブパラメータ数8B)でなく、30Bからpruningなどの技術を使って構築した8Bモデルで100Bモデルに匹敵する性能を獲得することを検討しています。なお、開発したモデルについては順次公開またはサービス提供していく予定で、すでに「PLaMo」シリーズをクラウドを介して提供(API事業)する「PLaMo Prime」を2024年12月にリリースしています。同年8月に、「PLaMo Beta」として迅速な社会実装を進めていたことが、多様なニーズの把握につながりました。その結果、事後学習においてどのような機能が必要かを検討するための貴重な情報が得られました。
国立研究開発法人海洋研究開発機構

国立研究開発法人海洋研究開発機構は、温暖化が進んだときに、地域レベルまたは企業レベルでどのようなリスクがあり、どのような対策を立てていくかという対策立案に特化したLLMの開発に取り組んでいます。最終的に、企業レベルでは、各企業において想定されるリスクと対策をTCFDレポートとして公開し、地域レベルでは、各地域における気候変動適応計画「温暖化対策実行計画」の策定を目指しています。これまでに予定していた学習データの収集を100%完了し、ベンチマークデータを構築。成果として、関連論文、自治体の温暖化対策、企業のTCFDレポートを収集するとともに、指示チューニング用データの自動生成が可能となっています。当初は、PDFファイルからの画像・テキスト抽出の精度に難がありましたが、「Docling」に変更することで精度の向上を実現しました。現在、自治体との協力体制を構築するとともに、企業との議論を開始しています。しかし、ボランティアベースのお願いになるため、自治体や企業からのニーズ収集と同時に、先方へのメリットを具体的に伝えることで取り組みを拡大していきたいと考えています。
株式会社ヒューマノーム研究所

株式会社ヒューマノーム研究所は、創薬を加速する遺伝子発現量の基盤モデル開発を進めています。今回、細胞の大規模データを使い、薬がどう効いているか、風邪をひくとどうなっているのかといったことが分かってくる予定です。そのために、1億細胞の遺伝子発現量データセットの作成を計画し、実施しました。世界中のデータベースをクロールし、生命科学系由来の細胞を5,000万以上収集するとともに、多様な臓器・疾患由来の細胞を5,000万以上収集しました。さらに今後、品質向上のためデータの前処理やメタデータの整備を実施する想定です。300Mを有する遺伝子発現量基盤モデルの開発を目指し、まずは3Mモデルから学習をスタート。当初、学習速度が遅いという課題に直面しましたが、AWSの担当者とのディスカッションによって、学習速度の改善を実現。この基盤モデルは、アカデミックな領域での利用も視野に入れ、先行研究でも公開されていないコードが見られる状況にし、産業界・学術界のバランスの良い公開方法を検討しています。同時に製薬会社へのヒアリングもスタート。しかしLLMや画像生成のように明確なイメージがあるモデルとは異なるため、まずは何らかの結果を出すことが大切であるという課題感を持って、取り組みを進めています。
株式会社EQUES

株式会社EQUESは、薬学分野・製薬業界に特化したLLMの開発に取り組んでいます。当初の計画では、学習データを構築し、薬剤師国家試験において、「GPT-4」の7割以上の正答率さなどの目標を掲げていました。学習データの構築においては、クリーニングに時間を要し、想定よりも遅れが生じていましたが、現在は順調に進捗しています。また、ベンチマーク評価用データとして、薬剤師国家試験のデータ化は完了しています。開発は「Qwen2.5」をベースモデルに決定し、事前学習のためのハイパーパラメータ探索アルゴリズム(D-CPT Law)を用いてハイパーパラメータを探索中。現在、すでに薬剤師国家試験ベンチマークの公開と評価実験が完了しています。既存のLLMは薬学分野の中でも、生物や病理の一問一答を比較的得意とする一方で、論理的な推論能力を要すると考えられる物理や化学の問題では正答率が伸び悩み、85%を超える高い正答率を達成したのは直近リリースされた「o1-preview」のみ(当時)。今後、精度向上に向けて様々なトライアルをしていく予定です。
SyntheticGestalt株式会社
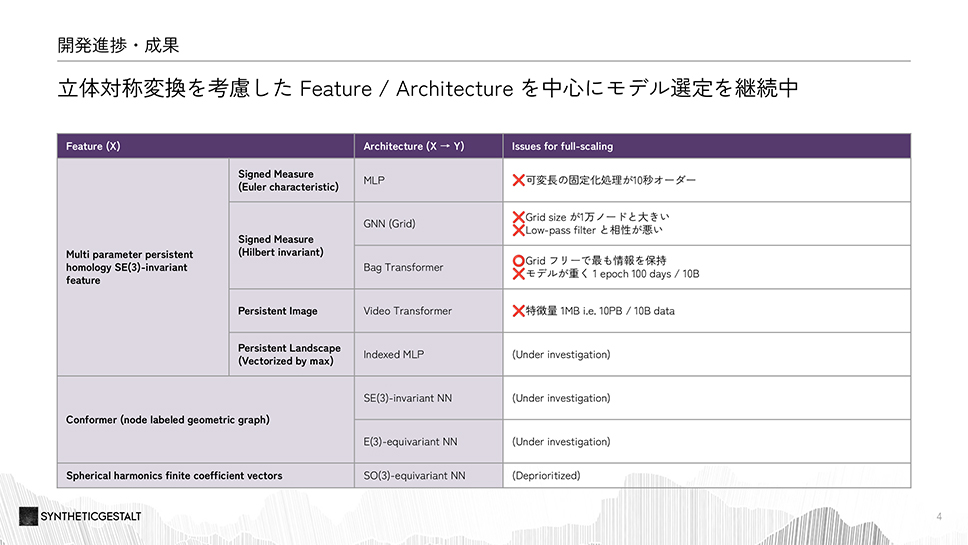
SyntheticGestalt 株式会社は、低分子に特化した基盤モデルの構築に取り組んでいます。100億件という膨大な化合物データに対して特徴量を作成し、それら全て使って事前学習を行い基盤モデルを開発します。AI創薬の世界には、TDC と呼ばれるベンチマークがあり、主要な23 タスクの全てにおいて世界トップ3に入ることを目標としています。開発した機械学習モデルの評価は、一般的なランダム・スプリットで行うと正しく評価されないため、スキャフォールド・スプリット (類似の骨格を持つ化合物をテストデータから除いた評価手法)を使用します。特徴量の設計においては、ニュートラルネットワークでの入力を可能にする必要がありますが、化合物を表現する際に、2Dではなく、3D・4Dでの表現を使用しており、開発の難易度を高めています。そうした課題に対して、数理的なアプローチを活かしたアーキテクチャの改良により基盤モデルとプロジェクトに柔軟性を加えることができました。

採択事業者からの発表の後に、NEDO(国立研究開発法人 新エネルギー・産業技術総合開発機構)AI・ロボット部 生成AIチーム チーム長 遠藤 勇徳より締めの挨拶があり、中間報告会を締めくくりました。
今回の中間報告会では、報告の合間に事業者同士での議論の時間が設けられ、各事業者が互いの知識をさらに深め、今後の開発に生かせる有益な情報を得る貴重な機会となりました。
生成AI開発コミュニティとしての役割も担うGENIACでは、今後も、事業者間での連携をより強化し、開発を促進してまいります。引き続き、各事業者が創意工夫を凝らし、さらなるイノベーションを追求することにご期待ください。
最終更新日:2025年11月5日