
2024/10/23
2024年8月5日(月)、GENIACの基盤モデル開発事業者と利活用企業との第2回マッチングイベントが開催されました。本イベントは競争力のある基盤モデルの開発とその社会実装の促進を目的としています。当日は、アプリケーション・ユーザー企業あわせて15社、関係者約100名が参加し、開発事業者によるプレゼンテーションの後、会場内に設置された開発事業者ごとのブースで意見交換などの活発な交流が行われました。本記事では、イベントの内容の一部を紹介します。
“Go to Market”へ向けた取り組み

マッチングイベント開催にあたり、経済産業省情報処理基盤産業室 室長補佐 杉之尾氏は、GENIACの3つの要素と現状の成果、本イベントの趣旨と今後に向けた具体的取り組みについて説明しました。
「GENIACは、日本の生成AIの持続的な開発力確保に向けて生成AIの開発力の底上げを図るとともに、それぞれのビジネス主体が創意工夫し挑戦できる環境を整えることがコンセプトのプロジェクトです」(杉之尾氏)
また、GENIACは①計算資源、②データ、③ナレッジという3つの要素から成り立っており、生成AI開発に不可欠な計算資源の提供、データ利活用の先進事例の発掘やデータホルダーとの連携支援、そしてコミュニティ運営を通じた生成AI開発に必要なナレッジの共有を通じて、日本の生成AIの開発力促進を図っていくことをあらためて説明しました。

2024年2月にプロジェクトを開始してから約半年が経過しました。これまでに計算資源の提供支援を2回実施し、データ利活用に向けた実証についても採択審査中で順次事業を開始していくとしています。
今後の計画としては、データAIの利活用促進に向けた支援、計算資源提供支援の継続、日本全体の開発力底上げとビジネス化を重視したAI開発支援、そしてアプリケーション開発企業やユーザー企業などをコミュニティに加えることで、AIの開発から利活用まで幅広い関係者の参加を促進する方針が示されました。
今回で第2回目となるマッチングイベントでも、基盤モデル開発企業、アプリケーション開発企業、ユーザー企業が参加し、直接的な意見交換や協業を通じて競争力のある基盤モデルの開発と社会実装につなげてほしいと抱負を語りました。
「本日のマッチングイベントが、将来の生成AI開発や利活用を見た際に、一つのきっかけとなったと言われるような会になることを願っています。」(杉之尾氏)
GENIAC開発事業者のご紹介
本イベントには下記の8開発事業者が参加し、プレゼンテーションを行いました。
マッチングイベントに参加した開発事業者
- 株式会社Preferred Elements
- ストックマーク株式会社
- 株式会社ABEJA
- 日本電信電話株式会社(NTT)
- 株式会社Kotoba Technologies Japan
- 富士通株式会社
- 株式会社リコー
- 大学共同利用機関法人情報・システム研究機構(国立情報学研究所)
株式会社Preferred Elements
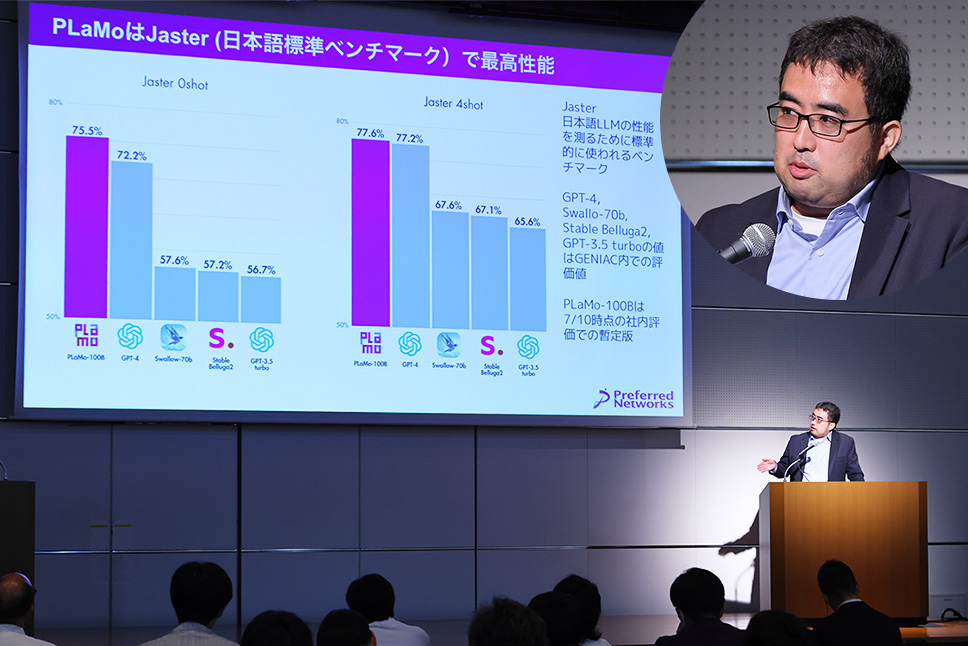
Preferred Networks(PFN)グループでは、AIチップや計算基盤、生成AI・基盤モデル、ソリューション・製品まで、AI技術のバリューチェーンを垂直統合し、産業への応用を進めています。GENIAC採択事業であるPerferre Elementsは、GENIAC事業において日本語性能に優れ、言語・画像・音声に対応したマルチモーダル1,000億パラメータの基盤モデル「PLaMo-100B」と、1兆パラメータの大規模言語モデルの事前学習の検証を進めており、「PLaMo β版」として近日中(2024年8月7日)に無料トライアル版を公開し、今秋に商用ライセンス版を展開する予定です。
ストックマーク株式会社

生成AIを活用した企業向け情報収集・資料作成支援サービスを提供するストックマークでは、2024年11月公募の採択を受け国内最大級の1,000億パラメーター規模の大規模言語モデル(LLM)を独自に開発しました。ビジネス利用で課題となるハルシネーションを抑制していることが特徴で、大手製造メーカーとの協業で特定企業に特化したカスタマイズモデルの開発も進めています。今後は汎用型のAIと特化型のAIを組み合わせたモデルの開発や、社内データの構造化を支援する取り組みを推進します。
株式会社ABEJA

ABEJAでは、企業のDX戦略の立案から必要なデータの生成・収集・加工・分析、AIモデリングまでのプロセスを「ABEJA Platform」として提供しています。また、DX人材の育成や運用サポートによって継続的な支援を提供し、汎用的なニーズや機能を各種のDX支援サービスとして提供するプラットフォーム事業を展開しています。採択されたプロジェクトでは日本語LLMの研究開発に加え、RAGとAgent機能の向上によって情報の精度とコストパフォーマンスを向上させ、LLMの広範囲な社会実装を目指しています。
日本電信電話株式会社(NTT)

日本電信電話株式会社(NTT)では、パラメーターサイズが70億と軽量ながら日本語に強い自社開発のLLM「tsuzumi」を提供しています。企業や業界に特化したチューニングを低コストで実現できるなどのカスタマイズ性が高く、図表読解などマルチモーダル性も備えています。今年3月に商用化され、3つの利用環境(オンプレ、プライベートクラウド、パブリッククラウド)と、3つのソリューションメニュー(CXソリューション、業界別EXソリューション、IT運用サポートソリューション)と組み合わせて利用できます。5月からはtsuzumiのAPIを一部無償提供するパートナープログラムを開始し、11月以降、Azureサービスとして簡単に利用できる仕組みを提供できるように準備を進めています。
株式会社Kotoba Technologies Japan

2023年9月に設立したKotoba Technologies Japanでは、音声基盤モデルの開発に取り組んでいます。具体的な活用例としては音声翻訳があり、英語と日本語のように異なる言語であってもビジネスのコンテキストに応じてリアルタイムに翻訳を行い、言語の壁を越えたコミュニケーションを支援します。また、開発した音声モデルはボイスクローニングにも対応しており、例えば私の声を15秒ほど渡すだけで、私の声を真似た日本語音声を生成できます。今回、GENIACに採択されたことで音声基盤モデルの技術開発が進展し、音声通訳やAI音声アシスタントなど幅広い分野での事業展開を計画しています。
富士通株式会社

富士通ではエンタープライズ向け生成AIフレームワークの研究開発を進めており、企業が保有する大量のデータを様々な用途で効果的に活用するための取り組みを進めています。特にハルシネーションの制御が求められる領域では、長年にわたって開発してきたナレッジグラフ技術を活用した二つの基盤モデルを開発することで、出力結果の根拠を説明可能になり信頼性を向上させることができました。このナレッジグラフを活用し複雑なタスクへの対応力を高めたLLM「Takane」は、今年9月のリリースを予定しています。
株式会社リコー

リコーではディープラーニング登場以前からAI開発に取り組んできていて、近年では自然言語処理に力を入れています。2022年には60億パラメーターの日本語LLMを独自開発し、その後130億パラメーターのモデル開発にも成功しました。同モデルの開発では「語彙置換継続事前学習(トークナイザの改良)」と「カリキュラム学習」の工夫によって日本語への対応能力を向上させています。同モデルの無償トライアルを提供しており、企業データ等を使用した追加学習ができる環境もサポートしています。既に自社製品の保守サービス業務においてもドメイン知識を埋め込んだカスタムLLMの活用を開始しています。
開発事業者とユーザー企業が活発に意見を交換







開発事業者のプレゼンテーションの後にはマッチングタイムが設けられました。それぞれの開発事業者のブースには、アプリケーション開発企業やユーザー企業の担当者が訪れ、活発な意見交換が行われていました。




GENIAC開発事業者とご参加いただいた企業からのコメント
最後に、第2回マッチングイベントに参加したGENIAC開発事業者とご参加いただいた企業のコメントを紹介します。
GENIAC開発事業者コメント
株式会社Preferred Elements

基盤モデルの研究・開発・販売を行う株式会社Preferred Elements(以下、PFE)では、GENIACで採択されたプロジェクトにおいて、日本語性能に優れ、言語・画像・音声に対応したマルチモーダル1,000億パラメータの基盤モデル「PLaMo -100B」と、1兆パラメータの大規模言語モデルの事前学習の検証を進めており、今秋に商用の「PLaMo Prime」の展開を予定しています。
「PLaMoの特徴は、学習データやアーキテクチャの構築を他社に頼らずゼロからフルスクラッチで構築した純国産の基盤モデルであることです。日本語LLMの性能を測定するベンチマーク『Jaster』においても、OpenAIのGPT-4を上回るスコアを示しています。また、10〜30億の小規模モデル「PLaMo Lite」についても、日本語の応答や日英翻訳で高いパフォーマンスを達成しています。」(岡野原氏)
PLaMoベースの独自モデル開発も進めており、企業内の独自情報を追加した専用モデルの構築や、社内サーバでのオンプレミス運用も可能です。今後は製造業、素材産業、医療、金融など専門領域での応用を目指しているPFEは、前回のマッチングイベントに引き続き2度目の参加となりました。
「第1回のマッチングイベントでは多くの参加企業が既にLLMを試用しており、独自のニーズや自社データの活用に課題を抱えていることが分かりました。また、サポート業務や製品開発の自動化など本格導入を検討されている企業では、計算リソースの費用対効果を気にされる声も聞いています。今回のイベントでは、PFEが独自開発したマルチモーダル1,000億パラメータのモデルをブースでお試しいただき、日本語での回答能力を実際にご確認いただけます。企業の独自データを組み込むための支援方法など、より踏み込んだお話ができることを期待しています。また、イベントで得られた新たなフィードバックを今後の提案やユースケースの創出に役立てて参ります。」(岡野原氏)
株式会社Kotoba Technologies Japan

独自の技術で音声基盤モデル開発を行うKotoba Technologies Japan。音声基盤モデルとは、テキストデータから自然で流暢なスピーチを作成するほか、ボイスクローニングなども可能にするテクノロジーです。CEOの小島氏は本年2月のGENIAC採択後の開発についてこう話します。
「採択後は開発スピードを加速させ、Microsoft Azure上での1日50万時間程度の音声データ学習を進めています。もともとのモデルは日本語のみでしたが、今は日本語と英語、両方の翻訳・発話が可能で、レイテンシーも1秒以下に下がりました。音声での入出力によって、『日本語で話した内容を瞬時に翻訳し、正確かつ流暢な英語で出力する(話す)』といったことが可能になりつつあります」(小島氏)
開発中のGENIACイベント参加の意義について、同社CTOの笠井氏に聞きました。
「開発の方向性を検討する上で、参加企業の皆さまとのディスカッションは大変参考になっています。例えば『テキスト入力が難しい工事現場で、音声入力を通じて生成AIを活用したい』といった建設業からのリクエストなど、我々では気づきにくいニーズやウォンツを発見できました。音声や動画を扱うドメインからのご相談も多く、バーターの可能性なども広がっています」(笠井氏)
近々にも成果の公表と社会実装を予定しているKotoba Technologies Japan。小島氏は「まずは “音声翻訳”というコンテクストにおいて、音声基盤モデルがビジネスや研究分野での日本語話者のサポート役となれれば嬉しい」と話します。
「前述の “音声to音声” の翻訳に特化したモデルについては、今年度中に商業化を進めます。並行して、翻訳以外のモデル開発も推進しており、研修や面接のシミュレーションなどに活用できるエドテック関連のPoCをすでに実施しています。その他、GENIACを通じたAPIでの技術提供についても随時進めてまいります」(小島氏)
イベントにご参加いただいた企業
中外製薬株式会社

2030年を見据えたDXビジョン「CHUGAI DIGITAL VISION 2030」を策定し、デジタル基盤の強化とAIを活用した新薬の創出に取り組んでいるのが中外製薬株式会社です。同社でDX推進を担当する石部氏は、イベント参加の感想について次のように話します。
「中外製薬では、生成AIを創薬による価値創造とDXによる業務効率化に活用したいと考えています。既に社内に蓄積されている日本語研究データを活用するには、日本語に強いAIモデルが重要な役割を果たすと考えています。今回のイベントでは協業の可能性など踏み込んだ議論ができ、非常に有意義な時間となりました。」(石部氏)
ITシステム面ではMicrosoft Azure、AWS、Google Cloudの3つからなるマルチクラウド環境を導入している中外製薬ですが、社内に埋蔵されているデータを最大限活用するには、より日本語に強い生成AI基盤が必要だとデータサイエンスグループの水谷氏は述べます。
「医療情報を社内で『知恵袋』的に活用したいニーズは多く、Med LM(医学特化モデル)の導入も進めていますが、日本語の扱いやハルシネーションにも課題が残ります。弊社ではRAG基盤を構築し、これらの課題に対する検証を進めている段階です。」(水谷氏)
また、創薬のみならず、約7,600人の社員全員の業務効率化に生成AIの活用を2023年8月より開始したと話すのはデジタル戦略推進部の家門氏。
「業務効率化の分野では、生成AI活用に対する現場からの期待が非常に高くなっています。社内の各部門での費用対効果を見極めながら、現実とのギャップを埋めていくことが現在の重要な課題です。今後は製薬・ヘルスケア業界での生成AI活用において先進的なユースケースを出していくことを目指し、社内での生成AI展開を積極的に推進していきたいと考えています。」(家門氏)
株式会社テレビ朝日

AIを業務効率化とコンテンツ制作などに活用する株式会社テレビ朝日。社内横断の「AI推進チーム」も組織され、今後さらに高度かつ専門的な活用を広げていきたいと考え、社内の課題について次のように話します。
「例えば、視聴率分析レポートは番組評価に関わる我々にとって重要なレポートですが、作成にかなりの時間がかかっています。レポートのベースだけでもAIで自動化するなど、可能なところは効率化し、本筋であるコンテンツ制作等のクリエーティブな仕事により多くのリソースを割くことが理想だと考えています」(小俣氏)
「私たちは動画のデータを多く扱っていて、保存の際にはタイムコードやシーンの詳細といったメタデータが必要です。これらのデータも、現在はスタッフが直接入力していますが、動画の内容を読み取って文章化するようなAIが導入できれば、効率も内容もアップデートできるのでは、と考えています。検索性の向上やデータ同士を連動させた活用も狙えますし、より詳細な内容の分析なども可能になるでしょう」(中山氏)
放送局という企業ならではのニーズがある中で、今後の国内での生成AIへの期待感については次のように話します。
「現状のLLMはテキストベースでの利活用が多いものの、画像、動画、音声に関わるAI技術のさらなる成長と社会実装を期待をしており、特に、日本の言語、文化、習慣に強い国産モデルの開発進捗には注目しています。英語圏に寄ったアウトプットが多い中で、より自然な日本語音声生成や、日本の風景や人物画像の生成、伝統文化やサブカルチャーなどにまつわる映像の正確な分析などが可能になれば、クリエーティブの面でも生成AIの活用場面を広げられると思います」(小俣氏)
同時に中山氏から、日本語対応は海外のLLMでも可能だが、小規模のクローズド環境での適応、安全性やセキュリティ、日本語性能に優れているという点で日本製のLLMに注目しているとのこと。そんな状況で参加した今回のイベントについての感想と期待感を次のように述べます。
「課題解決の実現度や、具体的なシステムの運用法に至るまで、各社とざっくばらんに話すことができました。特にキャッチアップしにくいスタートアップとの情報交換は新鮮で、社内で積極的に共有し、ディスカッションの種にしていきたいと思っています。今後も様々な面から、業界特性に対応可能な生成AIの進化に期待しています」(中山氏)
第2回目となるマッチングイベントでは、AI開発事業者、アプリケーション企業、そしてユーザー企業にとって具体的な議論ができる貴重な機会となったという声が多く聞かれました。企業や業界それぞれのニーズや課題を基盤モデルの改良に生かすことで、生成AIの社会実装に向けた動きがさらに加速していくことが期待されます。今後のGENIACの活動にも、ご注目ください。
GENIACトップへ最終更新日:2024年10月23日