2025/07/08
GENIACで採択される国産の生成AI研究開発の分野は多岐にわたります。その成果は、企業や自治体との協業・共創というかたちで、課題解決に寄与しています。
株式会社リコー(以下、リコー)と損害保険ジャパン株式会社(以下、損保ジャパン)は2025年3月に、保険業務に特化したプライベートなマルチモーダル大規模言語モデル(LMM)の共同開発を実施中(※)であることを発表しました。GENIACにおける取り組みの一つであり、文書や図表を活用し最適な回答を自動生成するAIの実用化を目指します。開発の目的、また現状や展望について、リコーの梅津氏、損保ジャパン石川氏にお話を伺いました。
※実施期間:2024年12月〜2025年4月。
<プロフィール>

梅津 良昭(うめつ・よしあき)
株式会社リコー リコーデジタルサービスBU AIサービス事業本部 本部長。2016年、リコーに入社。研究開発本部にてAI/IoT系のソリューション開発を担当。2021年から、デジタル技術開発センター所長に就任。言語、画像、音声など様々なAIを活用したデジタルサービスの開発を手掛ける。

石川 隼輔(いしかわ・しゅんすけ)
損害保険ジャパン株式会社 DX推進部 開発推進グループ リーダー。日本IBMでWatsonの製品開発に携わった後、2022年から損害保険ジャパンでDX推進に従事。開発チーム全体をリード。現在は生成AIを活用したプロジェクトに注力。
両社が歩んだ生成AIの実装プロセス――研究開発から現場活用へ
――両社はこれまで、どのように生成AIの開発・活用を進めてこられましたか。
梅津:リコーでは、以前から生成AIのR&Dに取り組んでいます。2020年頃から言語系AIの開発を加速させ、チャットボットや文章読解などのビジネス活用を模索してきました。その中で、企業から「AIに自社のデータを学習させて使いたい」といった要望が増えたため、オンプレミスで使えるプライベートLLMの開発に舵を切りました。
2021年以降は、LLaMA系をベースに日本語に最適化した独自モデルを自社開発し、小型化を進めてきました。一方で、企業内の文書活用の文脈では、OCRだけでは不十分な課題に直面。GENIACプロジェクトとして、本格的にLMMの開発に取り組むことになりました。
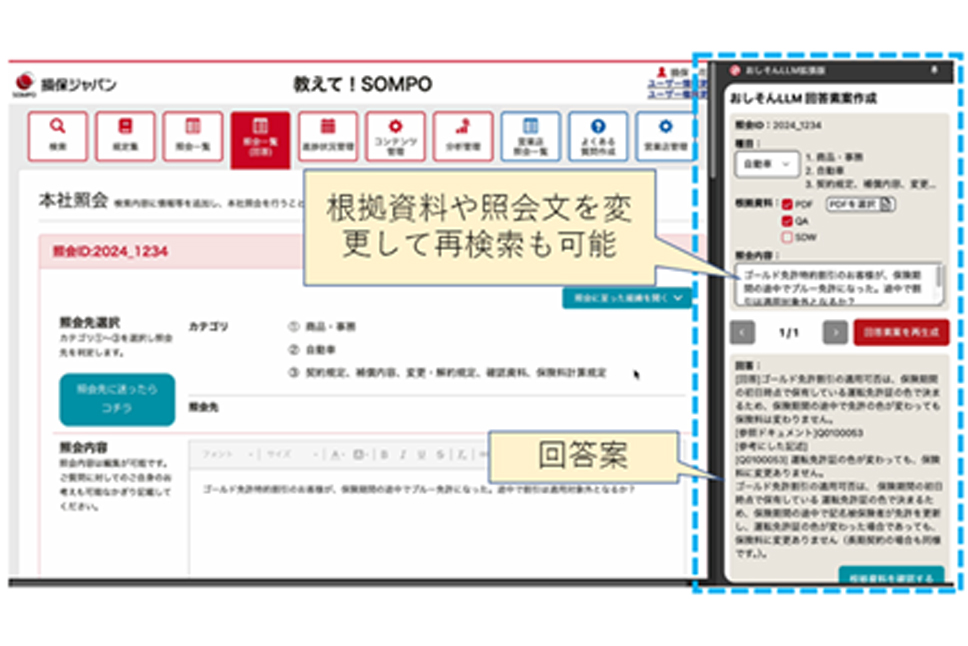
石川:損保ジャパンでは、2023年頃から本格的に生成AI施策に取り組み始めました。まずは社内規定照会システムを整備して、全社員が使えるようにした上で、各部門が様々なユースケースを試す体制を整え、それを元に「教えて!SOMPO」というシステムを整備しました。全国の営業拠点や代理店からの保険商品や事務処理に関する問い合わせに、自然文で答えられるようにする取り組みです。
――具体的に、現場ではどのような課題があり、どう対応されてきたのですか。
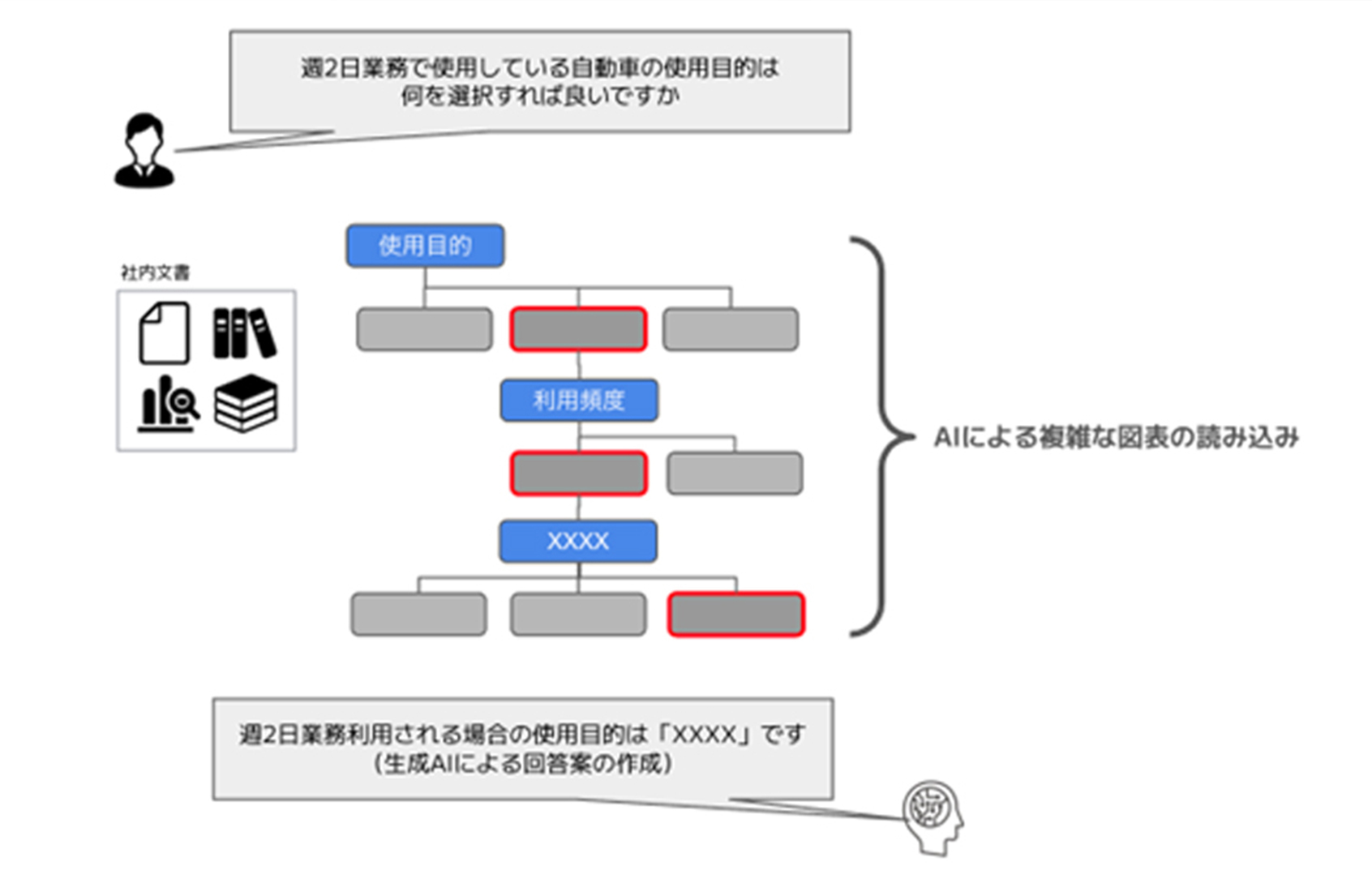
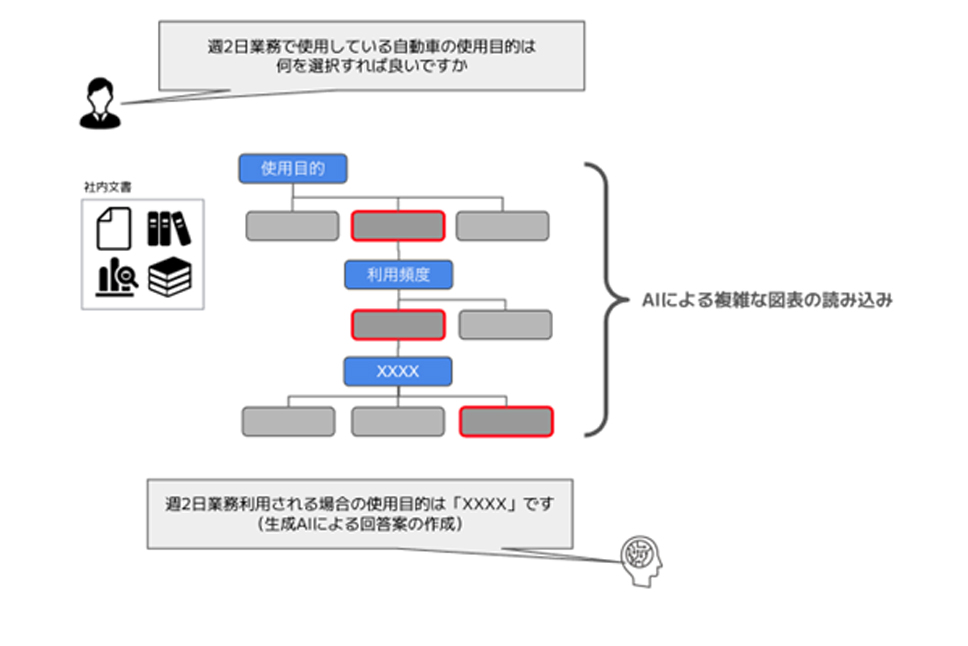
石川:現場でよくある業務課題に、保険の内容に関する判断の難しさがあります。例えば、物品が破損した際、何が補償の対象になるのか、基本的なことはマニュアルに書いてありますが、細かい物品名までは載っていません。間違いを避けるため、本社に確認したくなる人が多いのが実情です。こうした背景から、生成AIを活用し、現場からのメールでの質問に対する回答のドラフトを、自動生成できるようにしました。
現状では、AIが最終的な判断を間違うこともありますが、作成した回答文の8割程度はそのまま使えることが多く、業務効率が大きく改善されています。ただ、まだ完全にAIに任せられる段階ではなく、最終的な確認は人の目で行う必要があります。現在も、継続的に精度のチューニングを進めている段階です。
GENIACがつないだ共同プロジェクト。“AIに読ませる準備”もカギ
――両社が、今回の共同開発に至った理由と経緯を教えてください。
石川:保険文書には複雑な図やフローチャートが含まれていますが、生成AIはまだそういった非テキスト情報の理解が苦手です。そこで、リコーさんと共同でLMMを開発し、保険文書の読解・解析の効率化を推進したいと考えました。
梅津:Chat GPT 4やGeminiのような汎用モデルでは、日本特有のドキュメント――例えば、複雑なフロー図や細かい罫線などを正確に読み取るのが、非常に難しいんです。そこで我々は、GENIACの採択・支援を受けて、2023年末頃から高解像度な図表の読み取り精度向上に特化したモデルの学習・開発を本格化。2024年初頭には成果が出始め、損保ジャパンさんから提供いただいた実データでのファインチューニング・適用テストに着手しました。タイミング的にも、LMMの技術進展と我々の課題とが一致し、GENIACの枠組みで実現できたのは非常に良いご縁だったと感じています。
――現在、共同開発のプロジェクトはどの段階まで進んでいますか。
石川:現在は初期フェーズであり、保険業務関連の文書・図表や、問い合わせの実例を基にリコーさんサイドでプライベートLMMの開発を進めていただいています。並行して、モデルの検証準備も進めており、精度評価を自動化する仕組みを構築し、開発中のモデルの性能を迅速かつ効率的に比較・分析できる体制を整えようとしています。
――開発にあたり、データの取り扱いなどに関する懸念点はどう乗り越えられましたか。
石川:我々は金融業として、データの取り扱いには厳格な姿勢を持っています。ただ、本物のデータなしで生成AIの価値は出せません。そこで、実は2年ほど前から生成AIの活用に向けた社内調整を進め、システム部門やコンプライアンス部門と議論を重ねてきました。
弁護士の意見なども交えながら社内規定や運用方針の整理も進めてきた結果、今回のプロジェクトに関してもビジネス部門側からも前向きな反応が得られ、スムーズな体制で臨めています。今回の開発に必要な学習について、リコーさんからも詳細な説明をいただき、社内の理解を得たかたちです。
――そもそも、生成AI活用に対する社内理解を進めるためのポイントなどはあるでしょうか。
石川:私たちの場合は、AI活用の意義を経営層に理解してもらうため、社長にも生成AIツールを使ってもらっています。まず、トップがその効果を体感することが、組織変革の起点になると考えたからです。部長クラスについても、会議の音声データなどをAIに処理させ、要約を音声化してジョギング中に聞くなど、日常的に活用しています。
コストや業務効率化のみを語っても、腑に落ちない部分が残るのが現実です。“便利さの体感”こそが、AI活用への意識を根本から変えるカギになっています。
梅津:昨年まで、AIは“アイデア出しのための壁打ちツール”くらいに思われていたかもしれません。が、今はリサーチや文書生成まで実務に使える段階に進化しています。「思った以上に使える」ことを、社内で広く認識してもらい、イメージとギャップを埋めることが、浸透させるポイントだと思います。
――共同開発を進める中で、新しく見えてきたことなどはありますか。
梅津:現在は、他の企業からも実務で使われる高度なドキュメントを提供いただいており、LMMがそれらにどこまで対応できるかを試しています。「高解像度での読解+ファインチューニング」のアプローチで、一定の読解可能性が見えてきたのは大きな前進です。現時点では、対応できる部分とできない部分があり、後者については学習データの不足などが原因です。
またこれにより、企業側も「LMM側で読解精度を上げていくか」「既存のドキュメント構造を見直すか」といった、現実的な選択肢を検討できる段階に入ってきた感触があります。つまり、今後は企業内のデータそのものを、AIが読みやすく学習しやすい形式へと整えていくことの重要性が高まってくるでしょう。
金融・生保だけでなく、多くの企業がAIエージェントによる顧客サポート強化を重視しており、人手不足や店舗縮小の流れの中で、AIに長時間・高精度な応対を担わせる構想を進めています。AI開発に最適化できるよう、資料設計そのものを見直す機運が高まっているというのが、我々の実感です。
石川:我々としても、今後は“AIレディ”なデータの整備が不可欠だと考えています。保険業界ではA4 1枚に膨大な情報を詰め込んだ帳票が多く、AIに最適化されたドキュメント構造とは真逆の設計になっています。また、重要書類でも古いものだと元データが残っていない、といったこともありました。残っていれば、AIエージェント学習の大きな助けになっていたはずです。
梅津さんもお話された通り、こうした状況を改善するには、ドキュメント設計や情報の保存そのものを見直した上で、全体の業務効率や顧客価値を向上させるという、コスト構造全体の最適化まで見据えた発想が必要です。現時点ではまだ“AIが読みやすいデータ”には明確な定義がなく、それを企業が単独で整備していくのは限界があります。GENIACのような枠組みの下で、整備が進むことを期待しています。
梅津:元データの難読性や紛失といった問題は、製造業などでも広く起きています。例えば、現場向けのマニュアルをつくる部署には、開発部門からCAD図やパワポでつくられた図表などがそのまま渡されるケースが多く、元となる情報や構造は共有されていない――しかも、開発部門が作成した資料は変更できない前提で流れてくるため、現場では読みにくいと感じつつも、そのまま使わざるを得ないといった実態があります。こうした文書をLLMなどで読解しようとすると、結局は莫大なコストをかけて処理することになりかねないわけです。
私も、国内全体でAIエージェントを使ったサポートを本気で実現するには、情報をつくる側と、読む側の双方の歩み寄りとプロセス全体の最適化が今後不可欠になると、多くの企業との議論を通じて感じています。
現場で使えるAIへ。小さく始めて、大きく育てるLMM開発戦略を
――今後の共同開発の進め方や、企業としての目標などをお聞かせください。
石川:現在は、リコーさんから開発中のモデルを受け取り、自社のユースケースに合わせて活用する準備を進めている段階です。実際に使った結果などを基に、使い方なども相談し、次の展開を模索している状況です。すぐ現場投入というわけではなく、まずは段階的な検証・適用のフェーズとして位置づけています。
また、これまで1年ほど、質問と回答の検証にも取り組んでおります。実際に生成された回答と、最終的に採用された回答との差分などのデータ資産も蓄積していますが、画像や図表に関しては正直まだ手がついておりません。一時的に代替テキストなどによる対応に留まっていますが、将来的には、こうした図表情報も含めてAIに説明させるアプローチも視野に入れています。
梅津:内製化能力が非常に高い損保ジャパンさんでは、今回我々が開発したオープンソース版LMMのファインチューニングを自社で進め、実運用に近づけることが可能だと考えています。LMMで読解した視覚情報を含む処理を、既存の業務フローやシステムとどう結合させていくかは、技術的にも運用的にも難易度が高い課題です。また、検証後のフィードバックをどのように学習サイクルに生かすかについても、企業ごとに運用設計が求められる領域になります。
リコーとしては、こうしたLMM活用に必要なフレームワークや技術を提供し、自走できる体制づくりを支援することが役割だと考えています。最終的に、我々のモデルが選ばれるかどうかに関わらず、損保ジャパンさんがLMM技術を業務にうまく取り入れられる状態に持っていくことが重要だと位置づけています。
プラスして、「ドキュメント領域における生成AI活用はリコーにお任せください」と言えるポジションを確立したいとも考えています。“デジタルデータ × AI”の活用については多くの企業やベンチャーが取り組んでいますが、「こんな複雑な図やマニュアル、AIで扱えるの?」と疑問が出るような場面こそが、我々の強みが発揮されるフィールドです。例えば、、「エクセル方眼紙の解読は大得意です」という立場が築けると良いと思っています。製造業などで、情報技術がエクセルなどの非構造化データとして蓄積されており、埋もれている企業は少なくないでしょう。そういった社内ナレッジを活性化・可視化してAIイノベーションにつなげたい企業は、ぜひご相談いただきたいです。他にも、ドキュメントをRAG化(検索拡張生成)したい、マニュアルをAIで自動読解・生成したい、といったニーズに対する、技術支援の体制づくりを目指しています。
――生成AI開発や、導入を迷う企業や法人へのアドバイスをお願いします。
石川:現時点での生成AIの精度は決して完璧ではないものの、実用レベルとしては十分に価値があると捉えています。正解だけを目指すのではなく、途中のプロセスでどれだけ有用な支援ができるか。そこにこそ、AIの実用性があります。いきなり数億円規模の投資をするのではなく、スモールスタートで試しながら運用を考えていくのがベストではないでしょうか。
梅津:私も、石川さんのご意見に大いに共感します。実際、GENIACに関連するプロジェクトで様々な企業に参加を呼びかけましたが、成果至上の姿勢がネックとなり、合意に至らないケースは少なくありませんでした。
100%を目指さなくても、業務に役立つケースは多い。だからこそ「もう少し気軽に、AI開発にトライしてみませんか」という呼びかけを、これからも続けていきたいと考えています。
GENIACトップへ
最終更新日:2025年7月9日