GENIAC第1期では、日本における基盤モデルの開発力の底上げ・基礎的な開発能力の育成を目標に、大規模言語モデルを中心に開発を支援しました。大規模な計算資源とデータを用いたLLM開発には様々な試行錯誤が求められ、その過程でノウハウが獲得されるなど、日本のAI開発力の底上げにつながりました。
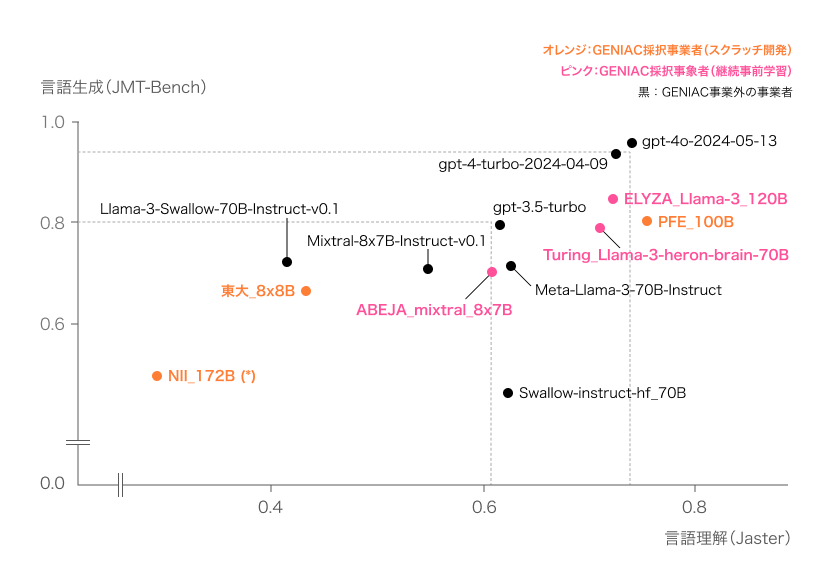
評価結果(図1, 2)から、GENIACプロジェクトによって開発された基盤モデルのなかには、日本語の理解・生成において、グローバルトップモデルに並ぶ非常に高い性能を持つものもあることが確認されました。特に日本語特有の表現や文脈理解においても優れた能力を発揮しており、今後日本での生成AI開発・利活用に向けて、さらなる発展が期待されます。
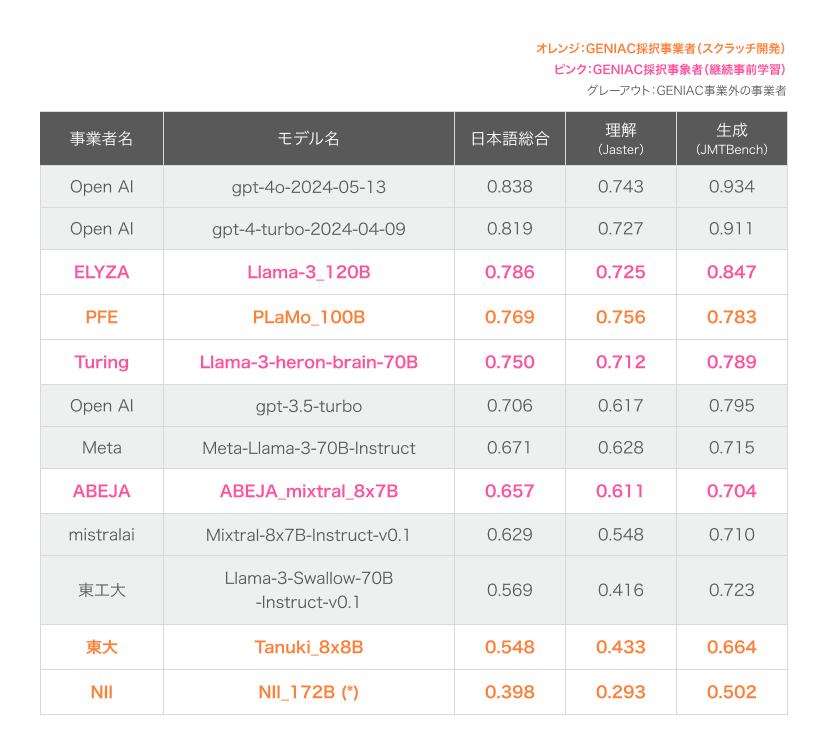
性能評価結果(日本語)(※2024年8月時点)
GENIACでは、公平性担保のため完全に未知なテストデータを用いて性能評価を行うことが重要であるという観点から、Weights and Biases社と協業し、ホールド・アウトデータ(最終的な性能評価を行うための非公開のデータセット)を生成・評価を行いました。以下の2つのベンチマークを用いて、日本語の性能評価を行いました。
- Jaster-GENIAC-v0.1: 日本語の論理的な包含関係、日本に関する知識や常識、日本語文章からの情報抽出など、日本語に関する能力を総合的に評価するベンチマーク
- JMT-Bench-GENIAC-v0.1: 日本語でのライティング、ロールプレイ、数学、コーディングなど、多様なタスクにおけるモデルの会話能力と応答性能を総合的に評価するベンチマーク
図1:性能評価結果(日本語)
注:
※NII_172B モデルについて︓Llama-2 の学習設定を踏襲して実験を開始しましたが、その途中で100Bパラメータ級のモデルになってはじめて顕在化する本質的な問題を発⾒、最適な学習設定を別途調査するに⾄ったことから、現在も学習を継続中のモデルです。
この検証に時間を要したことから、より最適な設定下で実施した期間終了までの学習(目標としていた学習量の約30%(4,000億トークン)分)の結果を記載しています。
図2:性能評価結果(日本語)※図1と同様の内容
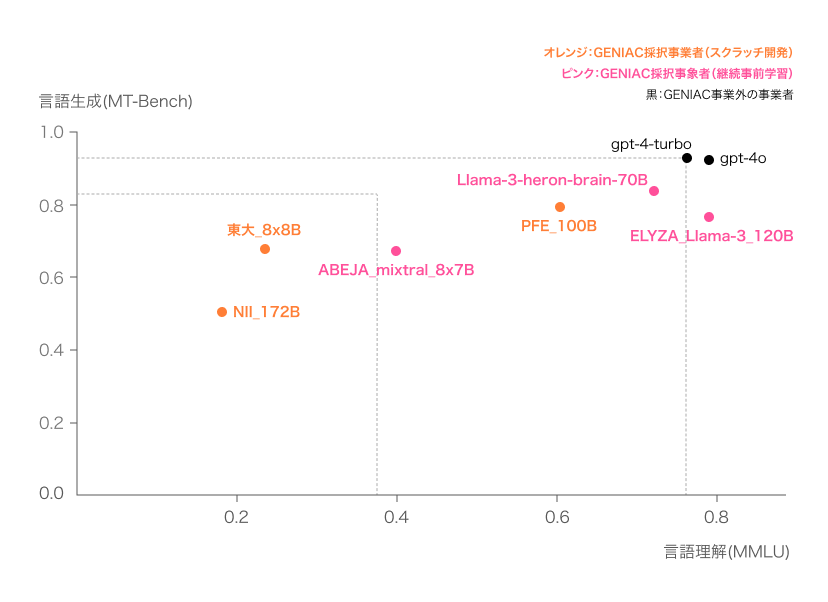
参考)性能評価結果(英語)(※2024年8月時点)
以下の2つのベンチマークを用いて、英語の性能評価を行いました。
- MMLU-GENIAC-v0.1: Massive Multitask Language Understanding(大規模マルチタスク言語理解)の略称で、人文科学、社会科学、STEM(科学・技術・工学・数学)など、合計57の学問分野における言語モデルの知識と理解力を評価するベンチマーク
- MT-Bench-GENIAC-v0.1: 英語でのライティング、ロールプレイ、数学、コーディングなど、多様なタスクにおけるモデルの会話能力と応答性能を総合的に評価するベンチマーク
注:
※Jaster-GENIAC-v0.1と- MMLU-GENIAC-v0.1については0-shotと4-shotの平均値を記載しています。
4-shotは、例えば、「1→奇数、10→偶数、101→奇数、10000→偶数」のように、例示を4つ挙げた上で、「11は奇数か偶数か」といった質問への回答を求めるものです。0-shotについては、例示を挙げずに、質問への回答を求めるものです。
最終更新日:2024年12月26日