
2024/8/26
On Tuesday, May 21, 2024, we held an online kick-off meeting for the projects selected from the February 2024 call, as well as an interim report meeting for the projects selected from the November 2023 call that started in February 2024.
In the first half, there was an explanation of the objectives and overview of GENIAC, presentations of the selected projects, and the development efforts undertaken by each project. In the second half, the four projects selected from the November 2023 call gave interim reports, followed by a Q&A session.
This article introduces some of the content from that day.
Domestic LLMs to Transform Japan and the World
First, Takuya Watanabe, Director of the Software Information Service Strategy Office at the Ministry of Economy, Trade, and Industry, explained the purpose and overview of the program and the role of the community to the selected projects from the February 2024 call.
"There are various challenges in the world, such as natural disasters and long working hours. Generative AI, which has the potential to solve many of these challenges, is becoming widespread. However, we are still in the early stages. There are many things we need to address to use AI safely across a wide range of fields. For Japan to safely use AI across broader areas and continue to create innovations, thus becoming a prosperous and proud nation, the development of generative AI is crucial. The participation of highly skilled software developers like you is indispensable. The goal of this program is to ensure the sustainable development of generative AI in Japan, enhance development capabilities, and create an environment where each business entity can be creative and take on challenges. This program is a living entity. We hope it will grow significantly with all of you," said Watanabe.
Next, Mr. Otani, Executive Officer of Microsoft Japan, gave a greeting to the selected projects from the February 2024 call.
"Congratulations to the three companies selected this time. As you start developing LLMs (Large Language Models), Microsoft, as a cloud vendor, will provide GPUs and various related solutions to support you in developing better LLMs as quickly as possible. It has been almost a year and a half since generative AI gained attention and began to be used in companies, and it is becoming clear that there is a growing need for multi-LLMs and SLMs (Small Language Models). Additionally, society requires multimodal usage, not just text but also voice, images, and videos. Ultimately, various LLMs and SLMs will be needed for different purposes, and Microsoft aims to support the global reach of domestic LLMs. We have recently released our own SLM, 'Phi-3.' We intend to share our development know-how through this program, work together on LLM development, and contribute to Japan's vitality and social implementation," said Otani.
Three New Companies Join GENIAC!
Next, the selected projects from the February 2024 call explained their project contents and the development efforts they would undertake with this selection.
[Three New Selected Companies]
- ELYZA Inc.
- Kotoba Technologies Japan Inc.
- Fujitsu Limited
Here are some highlights from their presentations.
ELYZA Inc.
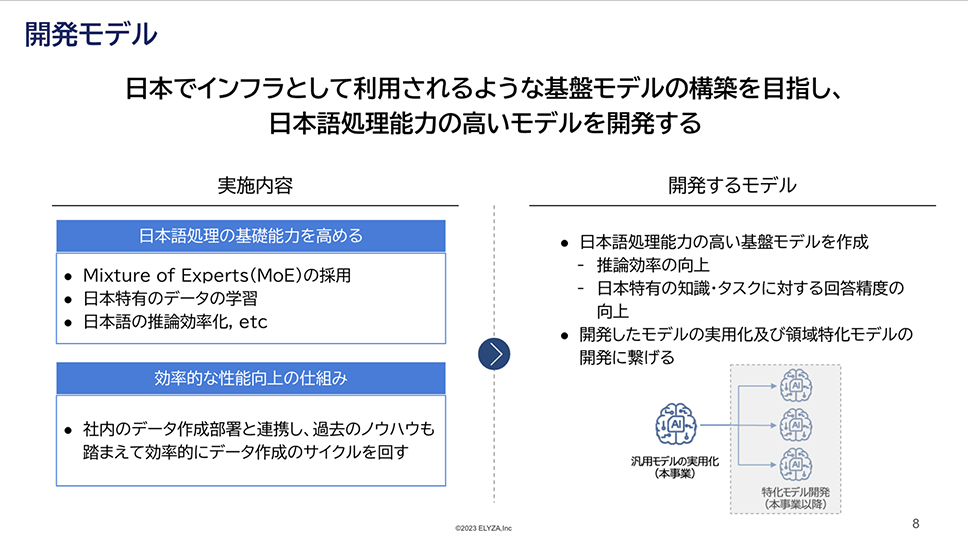
ELYZA Inc. is a company working on DX for white-collar tasks using LLMs. Since 2019, they have been active in both R&D and social implementation of LLMs. The company has previously announced applications and research results domestically. In March 2024, they built a 70 billion parameter model and released a demo site. They emphasize social implementation and have produced many examples of improving work efficiency by 30-50% through the introduction of LLMs.
"This time, we aim to develop a foundational model with high Japanese language processing capabilities, targeting its use as infrastructure in Japan. To enhance the basic ability to process Japanese, we will adopt MoE (Mixture of Experts), train with Japanese-specific data, and optimize Japanese inference efficiency. Additionally, we will collaborate with our data creation department, leveraging past know-how to efficiently cycle through data creation. Based on the results of this project, we aim to realize practical use of general-purpose Japanese models and develop and deploy domain-specific models," said Kota Kakiuchi, CTO of ELYZA Inc.
Kotoba Technologies Japan Inc.
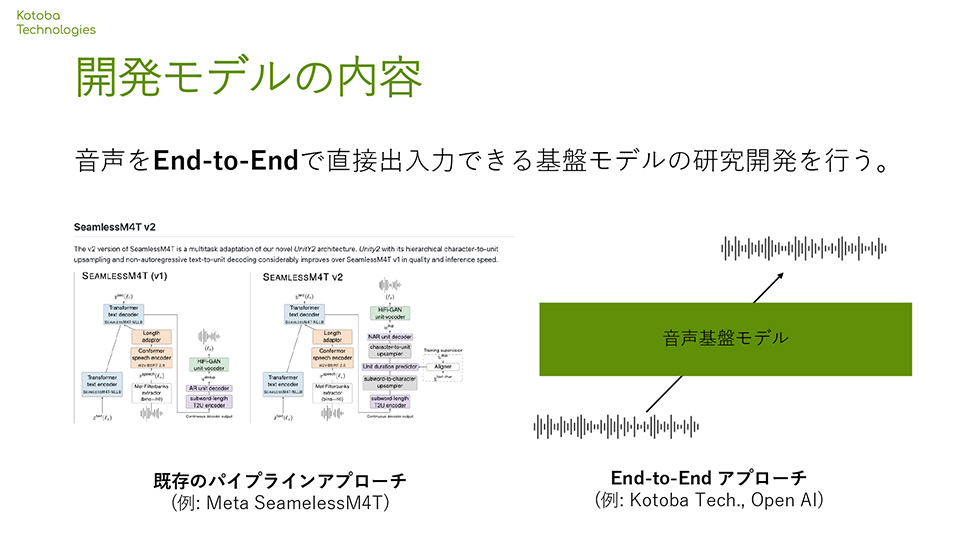
Founded in 2023 by members who have conducted generative AI research in American academia, Kotoba Technologies Japan Inc. is involved in developing LLMs using the supercomputer "Fugaku" and is currently developing state-of-the-art models for Japanese speech generation and recognition.
"In the GENIAC project, we will focus on R&D of a Japanese and English speech foundational model that can input speech waveforms directly and output end-to-end. End-to-end speech foundational models are still rarely developed globally. We plan to train foundational models with up to 7 billion parameters using large Japanese and English speech data and release some models to significantly contribute to the community. By publicly demonstrating the developed models, we hope to give everyone a strong impression of application development and receive feedback while addressing safety concerns. In our joint project with Tohoku University, our co-founder Jungo Kasai and Professor Keisuke Sakaguchi of Tohoku University will lead the team, sharing roles in collecting and evaluating speech model training data," said Hiroyuki Kojima, Co-Founder & CEO.
Fujitsu Limited
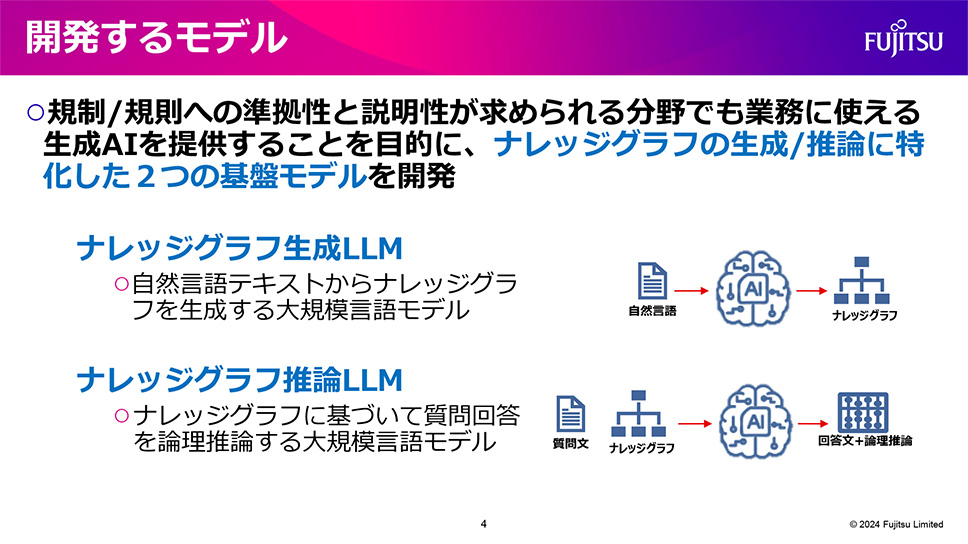
Fujitsu Limited, involved in developing hardware such as the supercomputer "Fugaku" and supporting DX realization using AI technology, has recently focused on R&D of generative AI for social implementation. They are working on developing highly reliable, specialized models that can be used in actual business operations.
"This time, we will focus on developing models that enhance reliability to address issues such as hallucinations. Specifically, we aim to develop models that can output in compliance with regulations and corporate guidelines, suitable for fields requiring explainability, such as legal. We believe that developing a foundational model specialized in generating and inferring knowledge graphs is essential. We will perform pre-training combining natural language and knowledge graphs, followed by fine-tuning. We aim to accurately answer tasks requiring logical reasoning," said Koichi Shirahata, Senior Project Director at Fujitsu Laboratories Ltd.
Achieving Results Despite Overcoming Troubles!
Next, the following four selected projects working on foundational model development gave interim reports.
[Companies that Gave Interim Reports]
- ABEJA Inc.
- StockMark Inc.
- Turing Inc.
- Preferred Elements Inc.
Here is an overview of their presentations and some comments from the presenters.
ABEJA Inc.

At ABEJA Inc., the team is organized into data preprocessing, model development and training, and infrastructure teams, implementing continuous pre-training with Mixtral 8x7 Billion's Japanese vocabulary extended version. They used Megatron-LM and Hugging Face for development, creating bidirectional conversion scripts.
[Report Overview]
- The tokenizer before vocabulary extension used about 400B tokens (including approximately 126B tokens of English and source code, and approximately 30B tokens of unique Japanese data).
- Continuous pre-training using Mixtral 8x7 Billion was developed and validated on Ubuntu on GCE (confirmed distributed learning operations) and conducted main training on GKE on COS.
- The issue of Loss gradually becoming NaN (Not a Number) after training was resolved by switching from fp16 to bf16.
[Comments from Presenter (Excerpt)]
"We have experienced common issues such as environment setup, model development, nan phenomena, communication errors, and node failures. If you encounter any problems, please feel free to contact us," said Kentaro Nakanishi of ABEJA Inc.
StockMark Inc.

StockMark Inc. focused on developing a foundational model that significantly suppresses hallucinations for business use, which requires high accuracy. By pre-training using business domain knowledge collected by the company, they aim to develop a highly accurate model.
[Report Overview]
- In addition to publicly available datasets, the company used a text dataset of 305 billion tokens, including business domain data they collected. For English, they sampled from the Red Pajama dataset (excluding Books).
- They trained a 100 billion parameter model of Llama 2 using 48 nodes of A3 instances.
- Although the initial learning progress (reduction in loss) was slower than expected, they adjusted by increasing the proportion of Japanese in the latter half of the training.
- Regarding process errors, it is crucial to detect automatic recovery, respond during maintenance, and decide how to handle node failures in advance, assuming some processes may stop.
[Comments from Presenter (Excerpt)]
"The model we are developing is also publicly available, and we have prepared a demo. If interested, please try it out. My message to everyone is that it is a challenging workload both mentally and physically, but please prepare as much as possible in advance and do your best," said Takahiro Omi of StockMark Inc.
Turing Inc.

Turing Inc. is working on realizing autonomous driving using multimodal AI. They aim for multimodal learning, adaptation to the driving domain, and large-scale deployment in a distributed environment.
[Report Overview]
- Utilized GCP's (Google Cloud Platform) "HPC Toolkit." By using blueprints, they can configure a large-scale computing environment optimized for GCP.
- Used Swallow-MS-7b (Mistral-MS-7b) and Llama3-8b (in training) as base models.
- The data is based on the Flan dataset from Google Research, with added responses (English). They machine-translated 50,000 items into Japanese instruction tuning data (about 100M tokens).
- Built the initial model for Japanese LLM (heron-brain-7b). It achieved the best Japanese performance compared to publicly available models in the 7B class.
[Comments from Presenter (Excerpt)]
"Starting in mid-June, we plan to conduct large-scale VLM (Vision-Language Model) training with 35 nodes. The key point is the application to autonomous driving, aiming for larger-scale model training and adaptation to the driving domain. We have realized the importance of a robust training environment for continuous experiments. Also, 'models and data do not scale easily,' so starting small and iterating might be the quicker route," said Yu Yamaguchi of Turing Inc.
Preferred Elements Inc.

Preferred Elements Inc. is working on five goals: "pre-training and additional training of 100B models," "instruction learning of 100B models," "pre-training and additional training for image modality," "additional training for audio modality," and "verification of pre-training of 1T models." Among them, pre-training of the 100B model is almost complete, recording 0.71 in the standard Japanese performance benchmark Jaster 4-shot as of May 13.
[Report Overview]
- Addressed intermittent interruptions and recoveries due to GCP maintenance and issues.
- Aiming for the highest performance in Japanese benchmarks with instruction learning of the 100B model by mid-July.
- From mid-July to August 15, they plan to establish, implement, optimize MoE methods, and verify model performance for the 1T model.
[Comments from Presenter (Excerpt)]
"We are considering several ways to provide this model. Since we develop everything from pre-training from scratch without using existing models, we are prepared for unexpected risks. We will verify safety in collaboration with external parties. Business development is also progressing in parallel. Completing the development of this model is not the end, and we will continue to work towards the next step including its commercial edition," said Daisuke Okanohara of Preferred Elements Inc.
Active Q&A sessions were held between each project's reports, sharing insights to solve specific issues raised by the questioners.
This interim report meeting was a valuable time for each project to deepen their knowledge and gain useful information for future development. We look forward to each project continuing to be creative and pursuing further innovation.
GENIAC Top PageLast updated:2024-02-01